Самообновляющиеся нейростикеры
Ссылка на телеграмовский стикерпак.
Когда я увидел, что сделали в process.studio, я сразу понял, что невозможно из этого не сделать стикерпак для телеграма. Вопрос лишь в том, кто успеет первым. А тут ещё в студии Лебедева вышел самообновляющийся генеративный стикерпак Стикератор.
Стикеры получились не очень детализированные, пиксельные, но душевные.
Злые:

Приунывшие:

В шоке:

Счастливые, насколько это возможно:

Опыта с нейросетями у меня никакого не было, поэтому мне помогал Саша Мохов, за что ему большое спасибо. Он помог выбрать инструмент и помогал советом в тупиковых ситуациях.
Картинки для обучения сети скачал с Эмоджипедии:
import lxml.html
from lxml.cssselect import CSSSelector as css
import requests
from urllib.request import urlretrieve
response = requests.get('https://emojipedia.org/people/')
tree = lxml.html.fromstring(response.content)
links = css('.emoji-list>li>a')(tree)
for l in links:
url = l.get('href')[1:]
if url == 'serious-face-with-symbols-covering-mouth/':
# stops downloading on specific emoji
break
print(url)
response = requests.get('https://emojipedia.org/people/'+url)
tree2 = lxml.html.fromstring(response.content)
imgs = css('.vendor-image>img')(tree2)
index = 0
for i in imgs:
index += 1
img_url = i.get('src')
filename = img_url.split('/')[-1].split('.')
filename[0] += '_'+str(index)
filename = '.'.join(filename)
print(' - '+img_url)
urlretrieve(img_url, '/Users/z/Downloads/Neuroji_images/'+filename)
Сеть обучил на бесплатном Google colab. Это офигенный сервис, можно запускать тяжёлые вычисления на серверах гугла и не греть свой ноутбук. Да и быстрее выходит. Результат обучения сохранил как два файла: структура нейросети и веса её связей.
model_17500.h5
model_17500.json
Модель делается долго, но её нужно сделать всего один раз, после этого для получения смайликов нужно совсем немножко ресурсов.
Смайлики генерятся другим питоновским скриптом. Он при запуске загружает модель нейросети, потом по таймеру создаёт стикеры и заливает их в пак с помощью либы python-telegram-bot:
%matplotlib inline
import telegram
from telegram.ext import Updater, CommandHandler
from PIL import Image, ImageDraw
from random import randrange
from io import BytesIO
import matplotlib.pyplot as plt
import numpy as np
from keras.layers import Dense, Flatten, Reshape
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Sequential
from keras.optimizers import Adam
from keras.models import model_from_json
import time
import sys
def sample_images(number=1):
global bot
global model
print("Hello, World!")
z = np.random.normal(0, 1, (number, z_dim))
gen_imgs = model.predict(z)
print('Generated {} images'.format(number))
gen_imgs = 0.5 * gen_imgs + 0.5
clear()
for i in range(number):
im_ar = (gen_imgs[i, :, :, :]) * 256.
pil_im = Image.fromarray(im_ar.astype('uint8'), 'RGBA')
pil_im = pil_im.resize((512,512), Image.NEAREST)
bio = BytesIO()
bio.name = 'image.png'
pil_im.save(bio, 'PNG')
bio.seek(0)
bot.add_sticker_to_set(user_id = 115178271,
name = 'neuroji_by_neuroji_bot',
png_sticker = bio,
emojis = '😶')
bot.send_message(chat_id='@zbottesting', text='{} neurojis added!'.format(number))
def clear():
global bot
stickers = bot.get_sticker_set('neuroji_by_neuroji_bot').stickers
for s in stickers:
bot.delete_sticker_from_set(s.file_id)
z_dim = 100 # Size of the noise vector, used as input to the Generator
number = 80
# load json and create model
json_file = open('model_17500.json', 'r')
model_json = json_file.read()
json_file.close()
model = model_from_json(model_json)
model.load_weights("model_17500.h5")
print("Loaded model from disk")
bot = telegram.Bot('851927713:Aa0hGqlACKcGD-deGbTX5BPYdfv3biNywRE') #FIXME paste your token here
updater = Updater(bot = bot, use_context=True)
j = updater.job_queue
updater.dispatcher.add_handler(CommandHandler('clear', clear))
def recurring_job():
try:
sample_images(number)
except: # catch *all* exceptions
e = sys.exc_info()[0]
bot.send_message(chat_id='@zbottesting', text='{}'.format(e))
time.sleep(60*5)
recurring_job()
recurring_job()
Рядом должны лежать файлы обученной модели:
model_17500.h5
model_17500.json
Этот код крутится на самом дешёвом сервере DigitalOcean. Причём я смешно запускаю: не просто питоновский файл, а целый jupyter notebook, на котором уже питоновский скрипт работает. Не уверен, что кроме меня так кто-то делает, но мне удобно, я к юпитеру привык.
Запускаю код так. Сперва подключаюсь к серверу по SSH:
ssh -L 8080:localhost:8080 root@64.225.28.54
Запускаю на удалённом сервере Jupyter notebook. Чтобы он продолжал работать после закрытия терминала, надо запускать его хитро:
nohup jupyter nonohup jupyter notebook --allow-root --port 8080 &
После чего ноутбук волшебным образом отрывается на localhost:8080, можно запускать в нём код на выполнение, закрывать вкладку браузера и терминал, и заниматься другими делами.
Ссылка на телеграмовский стикерпак.
Клёво было бы сделать естественный отбор, чтобы самые популярные выживали. Но, кажется, АПИ телеграма не отдаёт статистику об отдельных стикерах.
UPD: Время от времени вылезали ошибки и приходилось перезапускать скрипт в юпитере. Поэтому переделал по-нормальному: теперь слегка переделанный скрипт запускается по крону. Для этого открыл редактор crontab -e и добавил строчку
*/5 * * * * /usr/bin/python3 /root/cron-neuroji.py
Выбрать нужный интервал запуска можно на crontab.guru
Как сделать из своего имени поплавок
В Парке Интуиции мы с ребятами сделали маленький клёвый проект. Не спрашивайте, зачем он этому миру. Давайте считать, что это не сервис, а искусство.
Флотерея берёт любое имя и — шмяк! Делает из него поплавок. Наконец-то вы сможете больше узнать о себе и своих друзьях
Женя Арутюнов предложил написать про его устройство:
Сколько там переменных, как они связаны, как влияют на форму. Что такое грамматика, какая она. Как из текста получается набор переменных. Как устроены все интеграции, как был устроен процесс совместной разработки.
Вкратце
Поплавки собираются из заранее нарисованных секций. Не как попало, а в соответствии с правилами, описанными порождающей грамматикой. Она определяет разные варианты поплавков: какие в них типы секций, и в каком порядке они идут.
Последовательность получается рандомной, но эта рандомность зависит от содержимого текстового поля. Одинаковые значения будут рисовать одинаковые поплавки.
Входной СВГ файл
Поплавок собирается из секций, которые скрипт берёт из такого СВГ файла:
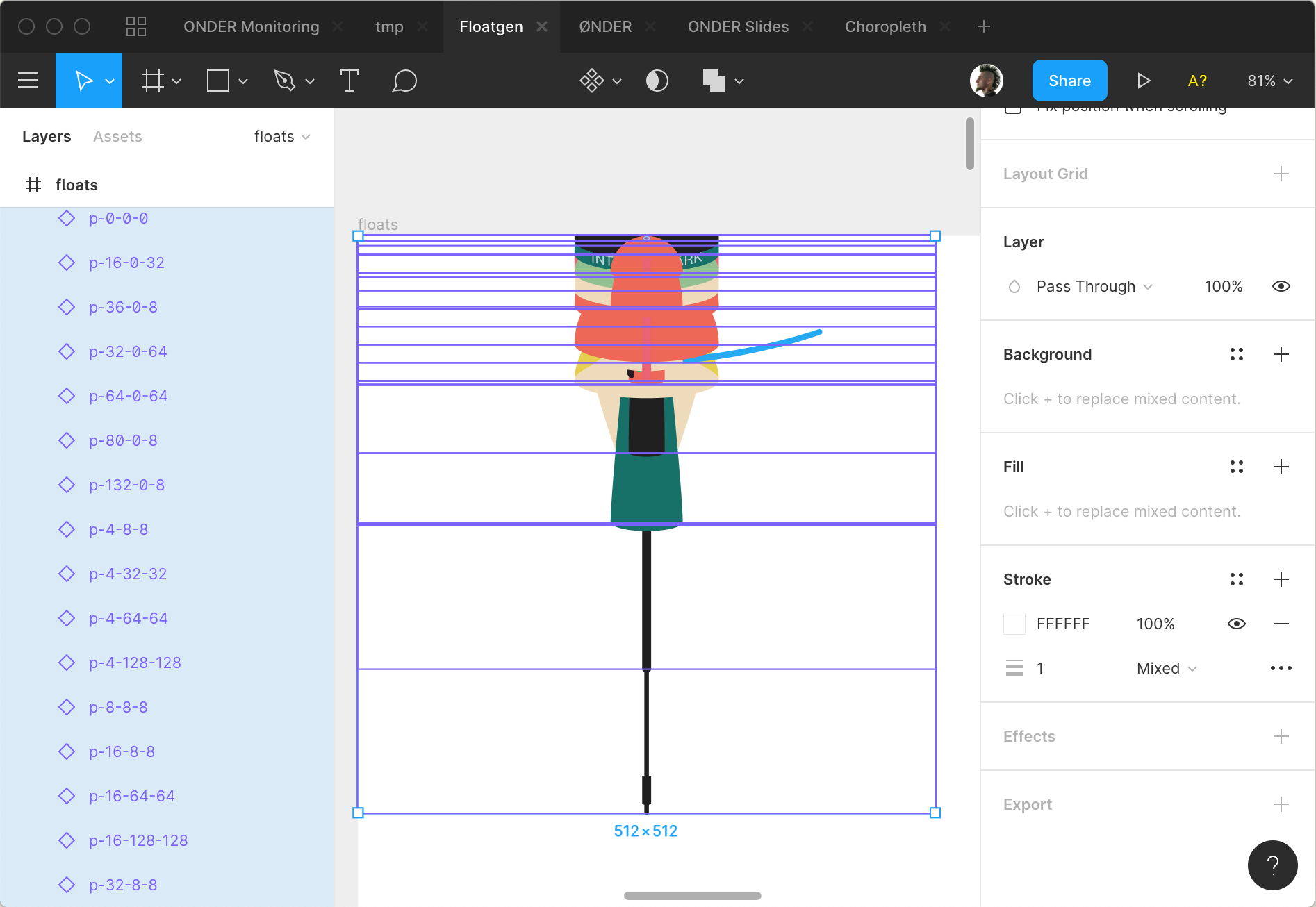
Все секции сдвинуты в верхний левый угол
Каждая секция лежит в своей группе.
Имена групп в формате p-16-32-100. Первая цифра означает высоту. Вторая — диаметр верхнего стыка. Третья — нижнего.
Порождающая грамматика
Это такая штука, которая может по заданным правилам создавать составлять последовательности слов. Вообще, грамматики нужны для генерации текстов, например, описаний монстров и титулов в играх. Но её можно использовать и не по прямому назначению. Например, ими генерят фракталы и космические корабли в СВГ.
Почему бы не использовать её для рисования поплавков? Каждая секция — как бы слово. И эти «слова» надо расставить в таком порядке, чтобы вышло грамматически правильное предложение — поплавок.
Для работы с грамматикой я выбрал библиотеку RiTa. Она понимает формат YAML.
Ниже покажу пример грамматики и расскажу, как она собирает поплавки из секций.
<start>:
- <type1>
- <type2>
- <type3>
- <type4>
<type1>:
- <0_8> <8_8> <8_8> <8_32> <water> <32_32> <32_8> <8_0>
<type2>:
- <0_8> <8_8> <8_8> <8_64> <water> <64_64> <64_8> <8_0>
<type3>:
- <0_8> <8_8> <8_8> <8_128> <water> <128_128> <128_8> <8_0>
<type4>:
- <dragonfly> <0_32> <water> <32_128> <128_8> <8_0>
<water>:
- <0_0>
Сокращённый, но по-прежнему рабочий пример поплавковой грамматики
В треугольных скобках токены — это такие штуки, которые могут превращаться в другие штуки. В примере ниже есть шесть секций, и в каждой из них говорится, чем тот или иной токен может стать. Если вариантов превращения несколько, они записываются один под другим.
В начале генерации есть единственный токен <start>, потом он в соответствии с правилами грамматики превращается в другие токены. Например, первое правило означает, что <start> может с равной вероятностью стать <type1>, <type2>, <type3> или в <type4>.
Допустим, мы получили из него токен <type1>. Посмотрим, во что может превратиться он:
<type1>:
- <0_8> <8_8> <8_8> <8_32> <water> <32_32> <32_8> <8_0>
Тут только один вариант. Зато какой длинный! Из токена неминуемо получается целая цепочка других токенов. Причём <water> в свою очередь неминуемо превратится в <0_0>. Потому что такое правило в грамматике тоже есть. И тогда последовательность токенов станет такой:
<0_8> <8_8> <8_8> <8_32> <0_0> <32_32> <32_8> <8_0>
Кажется, полученная последовательность токенов ни во что уже превратиться не может. Ведь в грамматике нет правил для превращения, скажем, <0_8>.
Но превращения ещё не закончены. Фокус в том, что некоторые правила грамматики создаются скриптом в зависимости от того, какие секции поплавков нашлись во входном СВГ файле.
Происходит этот так. Мы берём из входного СВГ все секции и запоминаем их в массиве. У каждого сегмента в массиве есть свой индекс, по которому его можно этот сегмент узнать и нарисовать на экране.
Для каждого сегмента мы добавляем в грамматику правило. Например, в массиве есть сегмент p-8-8-100 с индексом 2. Вспомним, что в названии секции первая цифра означает высоту, а последние две — верхний и нижний диаметры секций поплавка.
При его обработке в грамматику добавится правило:
<8_8>
- 2
То есть, секция поплавка с верхним радиусом 8 и нижним радиусом 8 может превратиться в секцию номер 2 из массива секций
Допустим, обработав все секции поплавков из входного СВГ, мы добавили такие правила:
<0_8>
- 0
- 1
<8_8>
- 2
- 3
<8_32>
- 4
<0_0>
- 5
<32_32>
- 6
<32_8>
- 7
<8_0>
- 8
Тогда наша строка
<0_8> <8_8> <8_8> <8_32> <0_0> <32_32> <32_8> <8_0>
может превратиться в
1 3 2 4 9 6 7 8
Поскольку некоторые токены, например <0_8>, имеют несколько вариантов превращения, итоговая последовательность может выйти немного другой.
Поздравляю! Мы получили последовательность индексов секций. Теперь остаётся вытащить секции с такими индексами из массива и нарисовать их одну под другой. И поплавок готов!
Делаем из имени поплавок
Когда в грамматике есть несколько вариантов превращений, один из них выбирается рандомно. Это обеспечивает многообразие возможных форм. Однако, чтобы одинаковые значения в текстовом поле создавали одинаковые поплавки, нам надо сделать эту рандомность зависимой от значения текстового поля. Библиотека RiTa может сделать рандомность предсказуемой:
RiTa.randomSeed(pseudoRandom);
Одинаковые значения pseudoRandom будут создавать одинаковые поплавки
На вход randomSeed() принимает число. А у нас в текстовом поле строка. Значит нам надо научиться из этой строки делать число. Нашёл для этого такую функцию на стековерфлоу, работает отлично:
function hashCode(str) {
return str.split('').reduce((prevHash, currVal) =>
(((prevHash << 5) - prevHash) + currVal.charCodeAt(0))|0, 0)
}
Арбайтен!
Совместная работа над грамматикой
Чтобы вместе весело работать над грамматикой и не лезть каждый раз в код, засунули правила в гуглотаблицу:
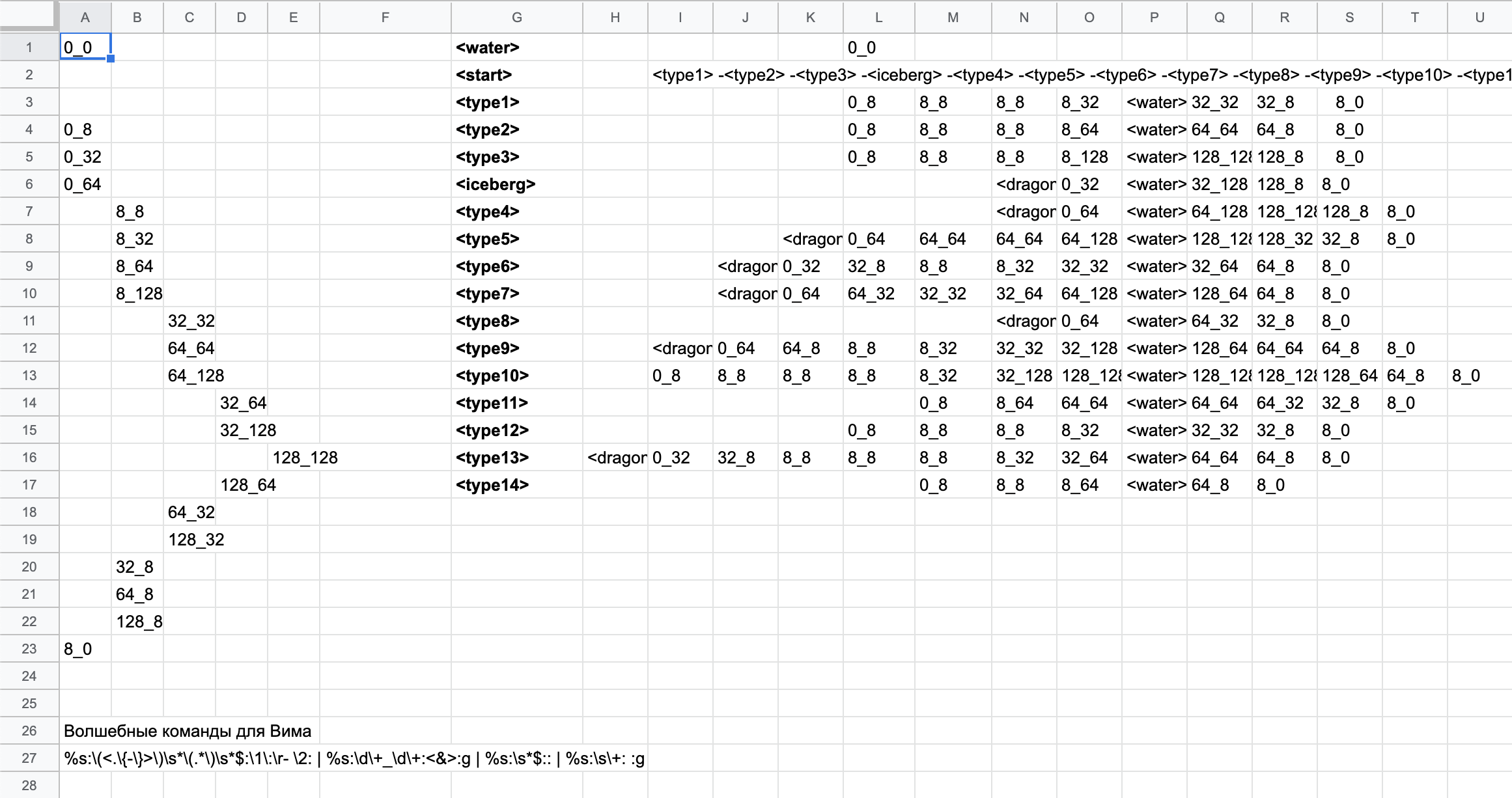
Слева я расставил все доступные в СВГ виды секций.
Справа, начиная со столбца G — правила грамматики. Тут можно использовать только те виды секций, которые перечислены слева.
Внизу — регулярное выражение для любимого текстового редактора Вим. Вставляю в Вим данные из правой части таблицы, запускаю команду, вставленная таблица преобразуется в формат YAML, который можно вставить в код. Знаки табуляции меняются на пробелы, лишние пробелы удаляются, и т. д.
Круги на воде и стрекоза
Они по сути — те же секции поплавков. Они лежат в том же входном СВГ файле, их положение в поплавке определяется грамматикой. Однако, они имеют хитрые размеры, чтобы грамматика не спутала их с какой-нибудь другой секцией. У воды размер верхнего и нижнего радиусов <0_0>, а у стрекозы <256_256>.
Такой подход позволяет на уровне грамматики определять,
- на каких секциях стрекоза может сидеть, а на каких — нет.
- Насколько часто стрекоза будет появляться.
- Между какими секциями поплавка будут расходиться круги по воде.
Удобно держать такие настройки в грамматике, это упрощает программу.
Итог
Кратко отвечу на Женины вопросы:
Как из текста получается набор переменных. Сколько там переменных, как они связаны, как влияют на форму.
Переменная одна, она делается из строки и является её хешем. То есть даже у почти одинаковых строк хеши будут сильно отличаться.
Эта переменная делает построение поплавка предсказуемым, определяя, какой из нескольких возможных способов превращения каждого токена будет выбран.
Что такое грамматика, какая она.
It’s breathtaking! They are all breathtaking!
как был устроен процесс совместной разработки.
Секции ребята рисовали в Фигме, дико удобно. Грамматику вместе редачили в таблице.
Перевёрстка данных о миграции
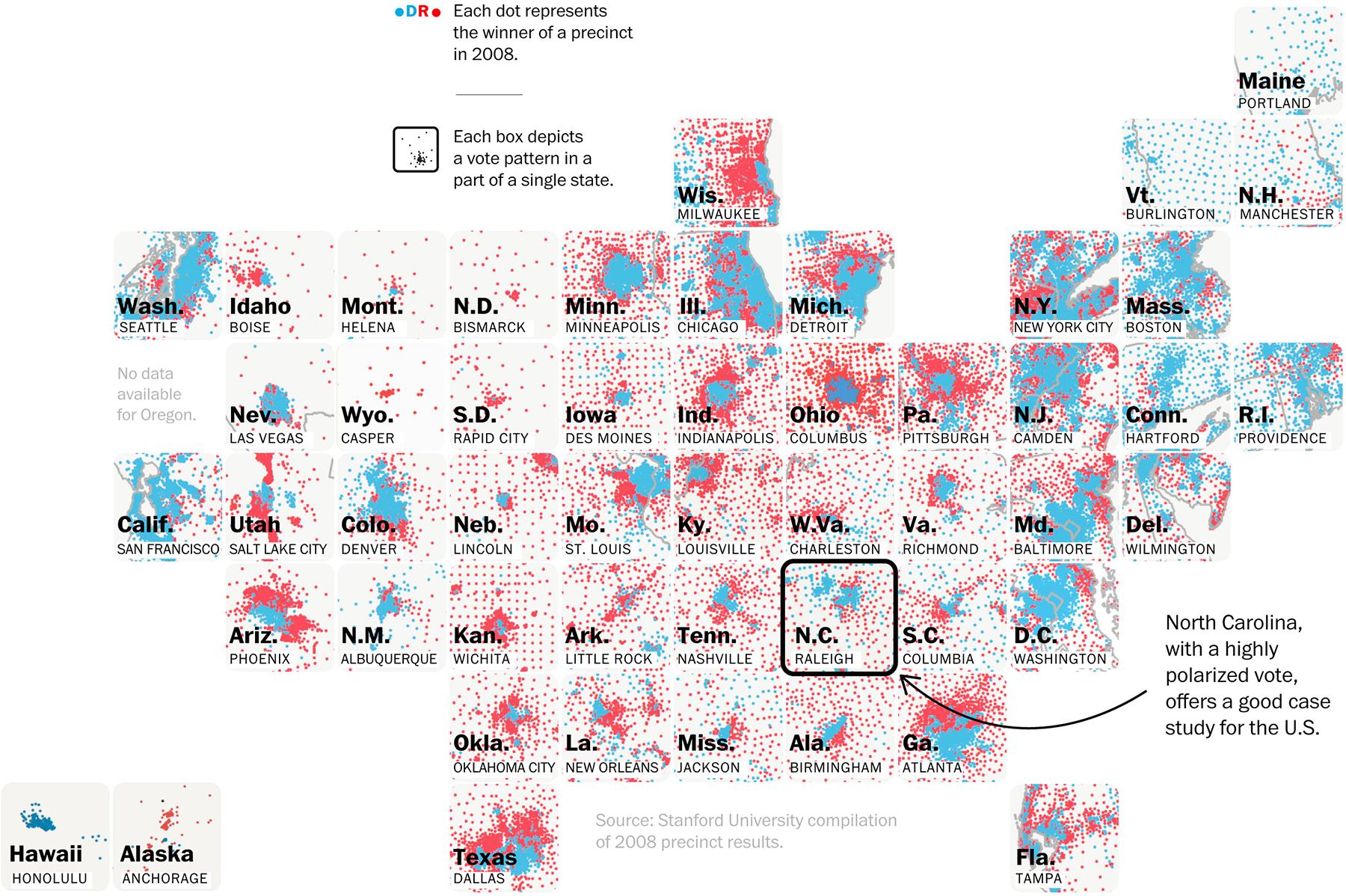
Росстат нарисовал такое:
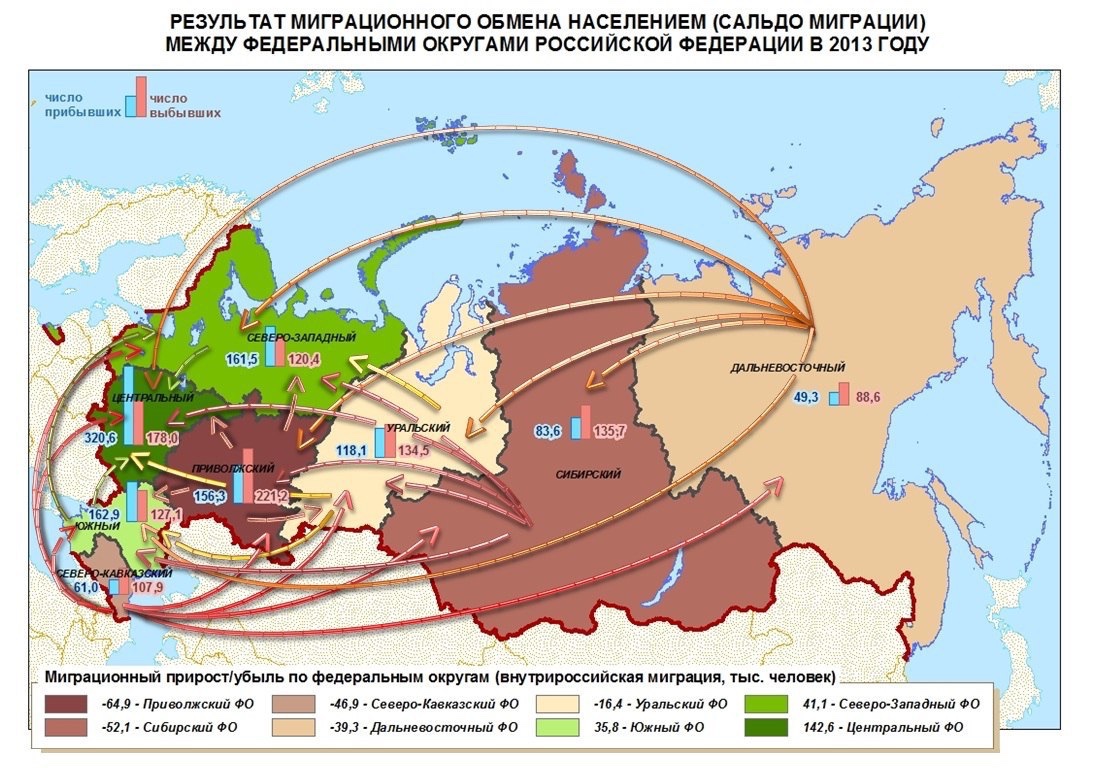
Округи можно вывести списком, не обязательно привязывать к карте. Стрелки всё окончательно запутывают: почему они делятся на сегменты? Важен ли их цвет? Куда уехало больше всего жителей ЦФО? Какой процент людей уезжает?
Было бы круче показать таблицей. В строках — откуда, в столбцах — куда уезжают. В исходной визуализации такой инфы нет.
Нажожу исходные данные на сайте Росстата. Да они прекрасны, всё как я и хотел :–) Даже больше: тут инфа разбита на городские и сельские поселения. По каждому федеральному округу можно посмотреть, сколько человек переехало из сёл в города, а сколько из городов в сёла.
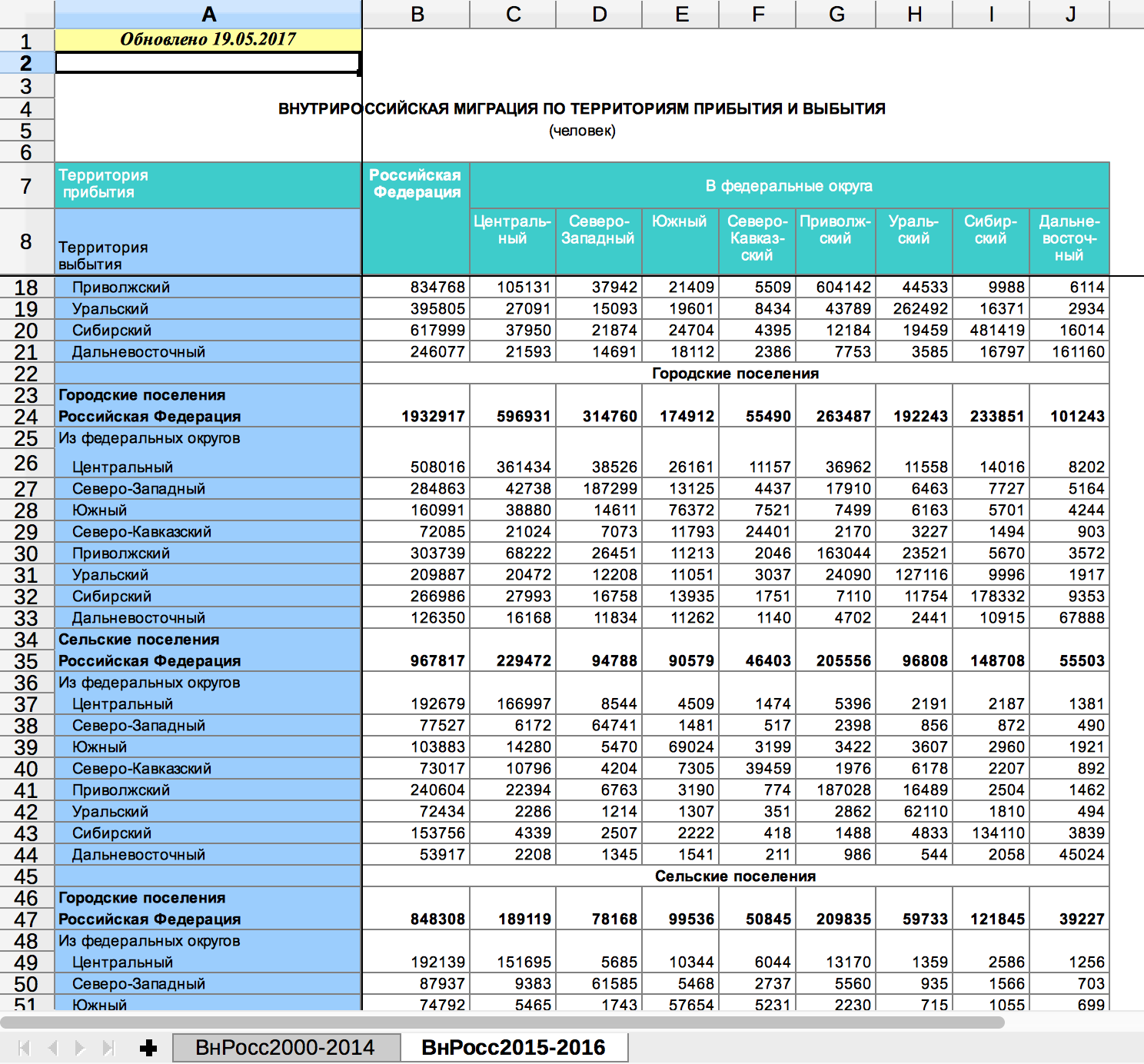
Попробую для начала визуализировать в Табло. Сейчас данные в виде разреженной таблицы, надо сделать её плотной. То есть такой, чтобы в каждой строке было указано: из какого ФО, из города или из села, сколько человек переехало, в какой ФО, в город или в село. Часть работы делаю вручную:
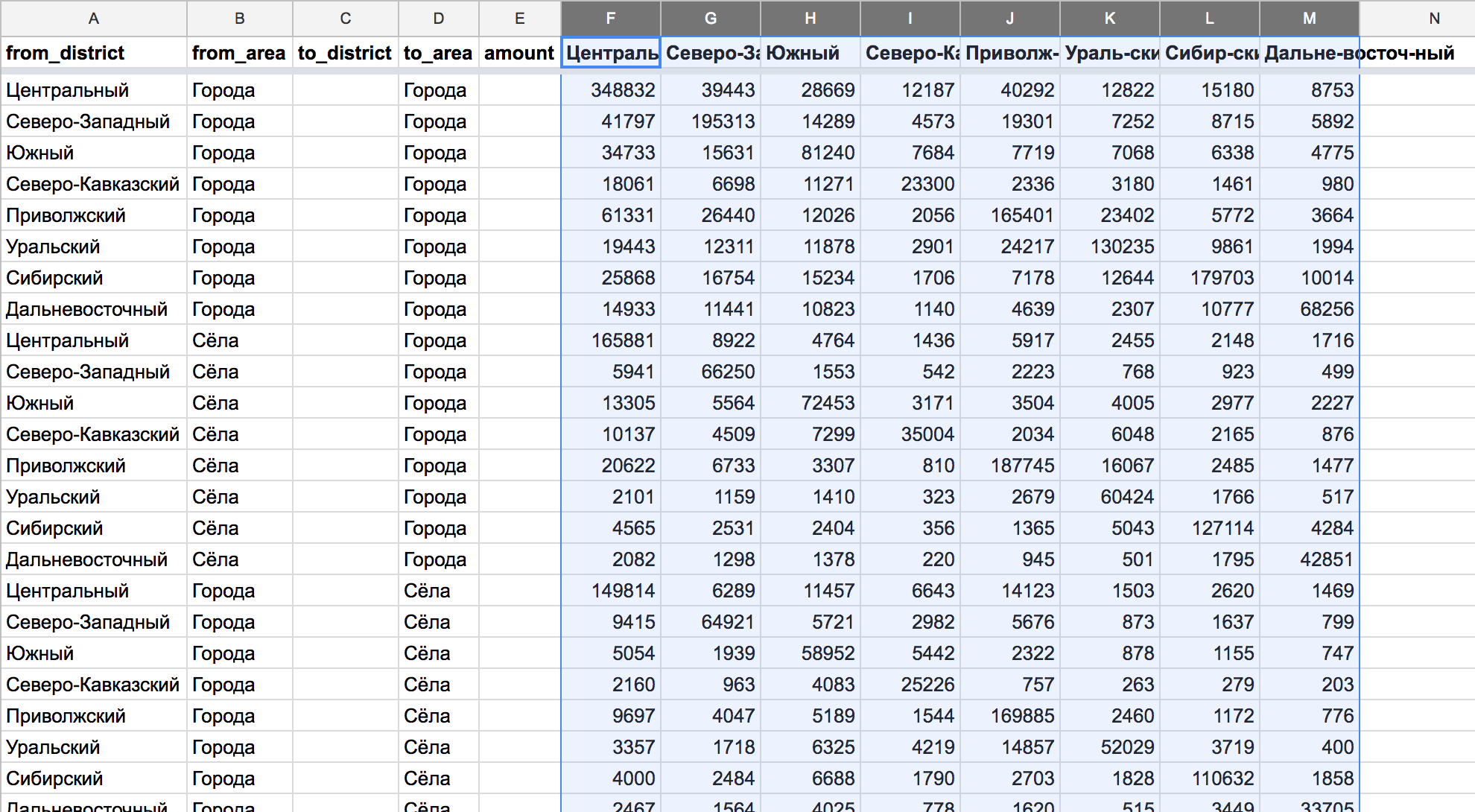
Выделенными данными надо заполнить столбцы to_district и amount. Тогда в каждой строке будет по одному числовому значению, как нам и надо. Вручную делать это долго, к счастью, Табло умеет так:
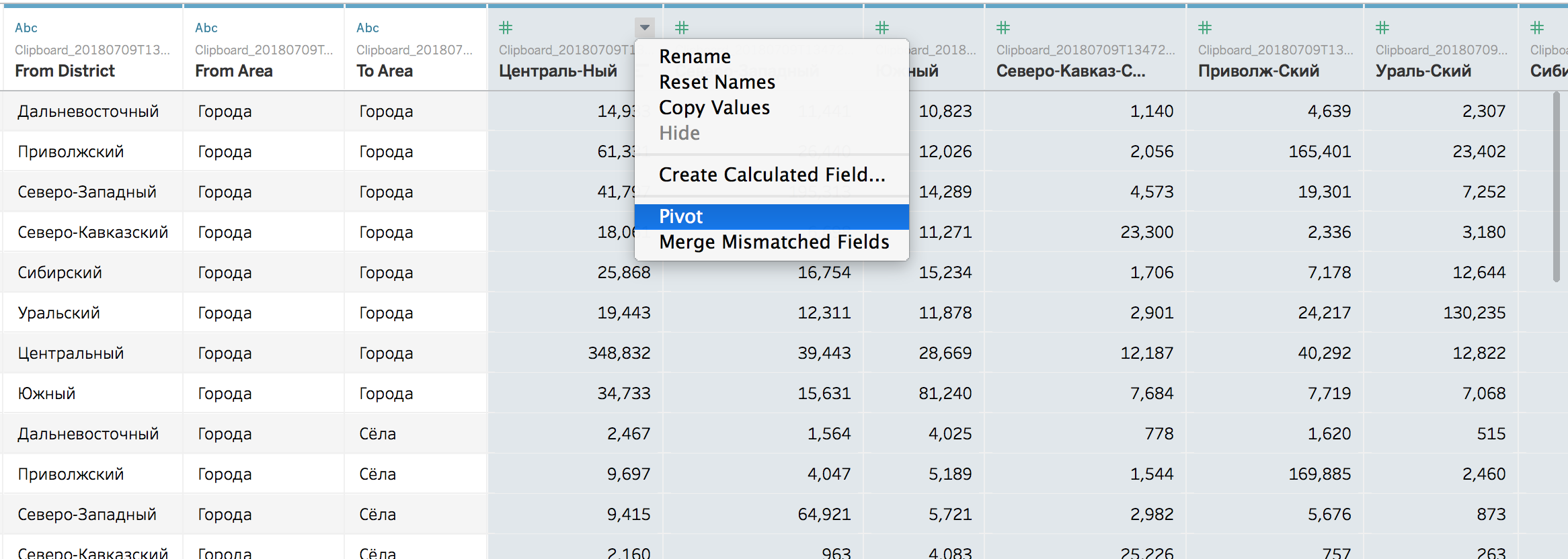
Ррраз — и данные в правильном формате:
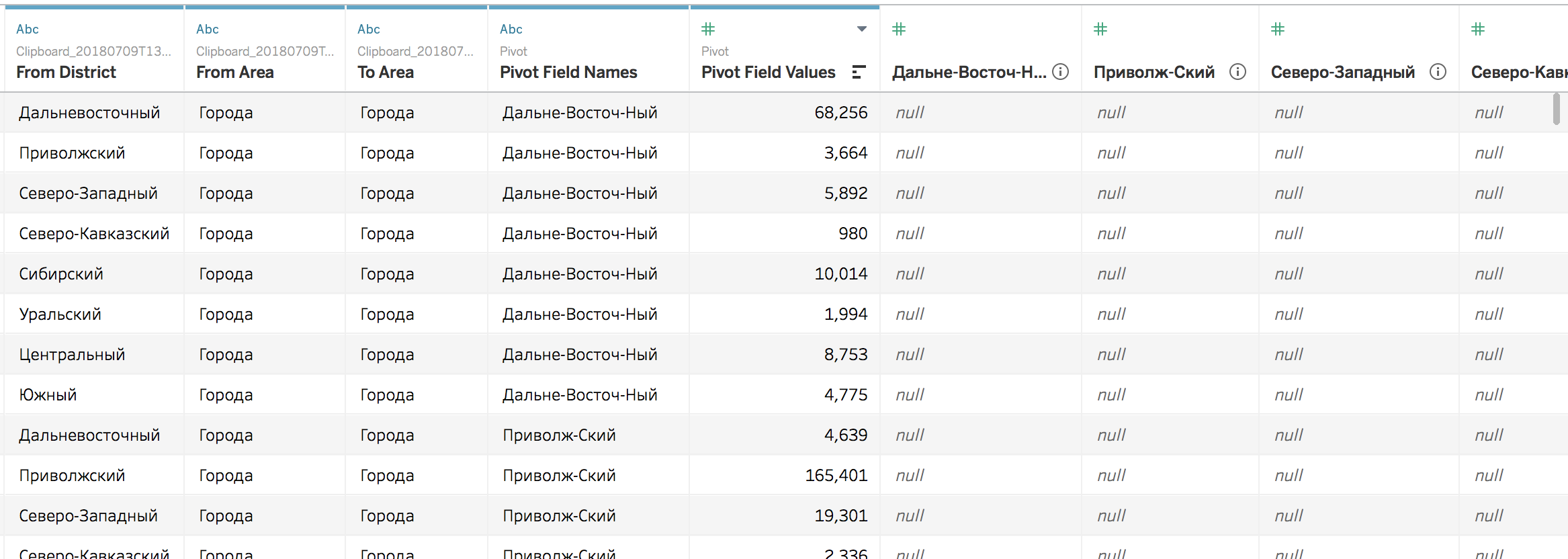
Здорово. Попробуем визуализировать:
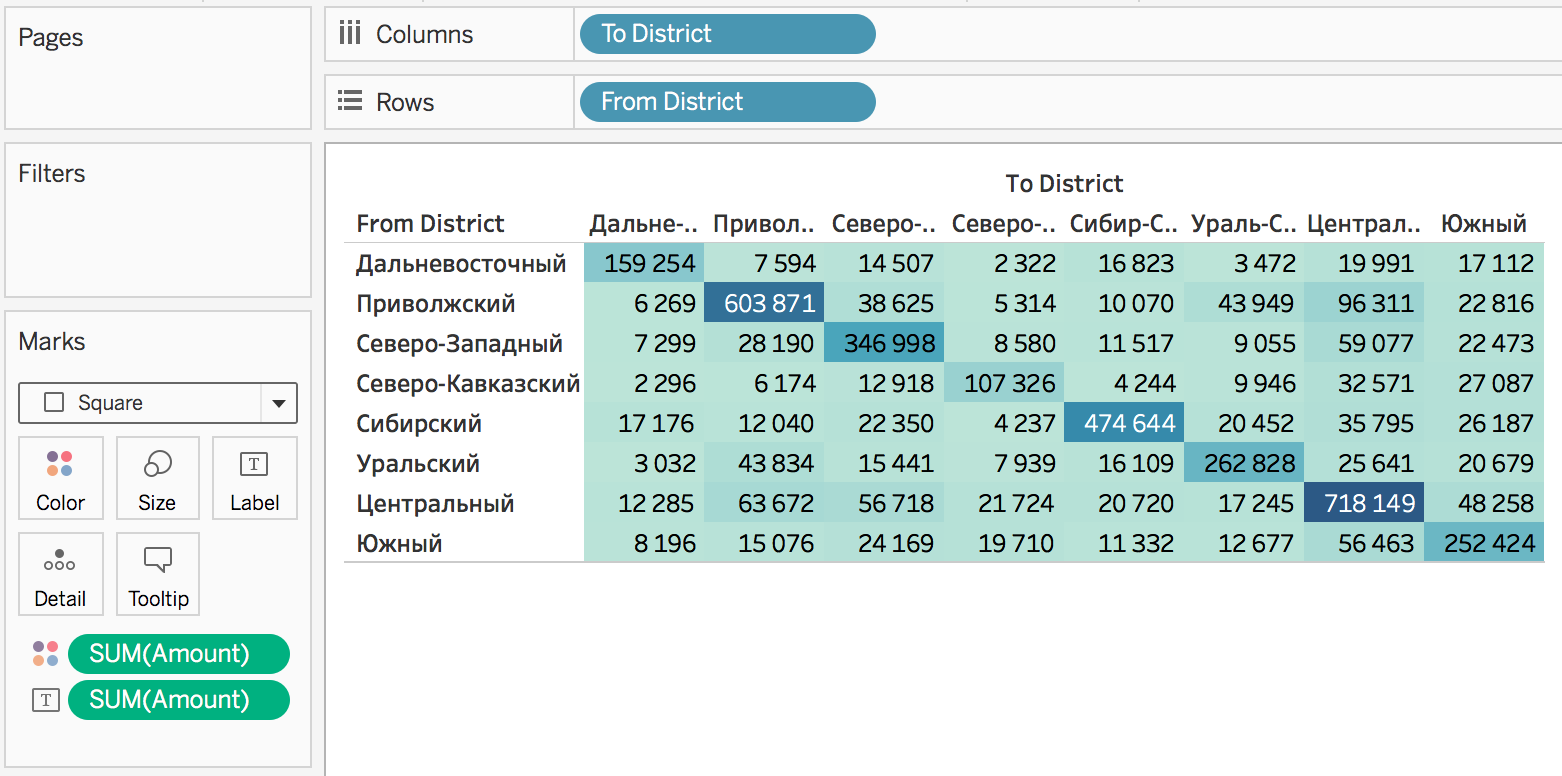
Теперь посмотрим миграцию между сёлами и городами:
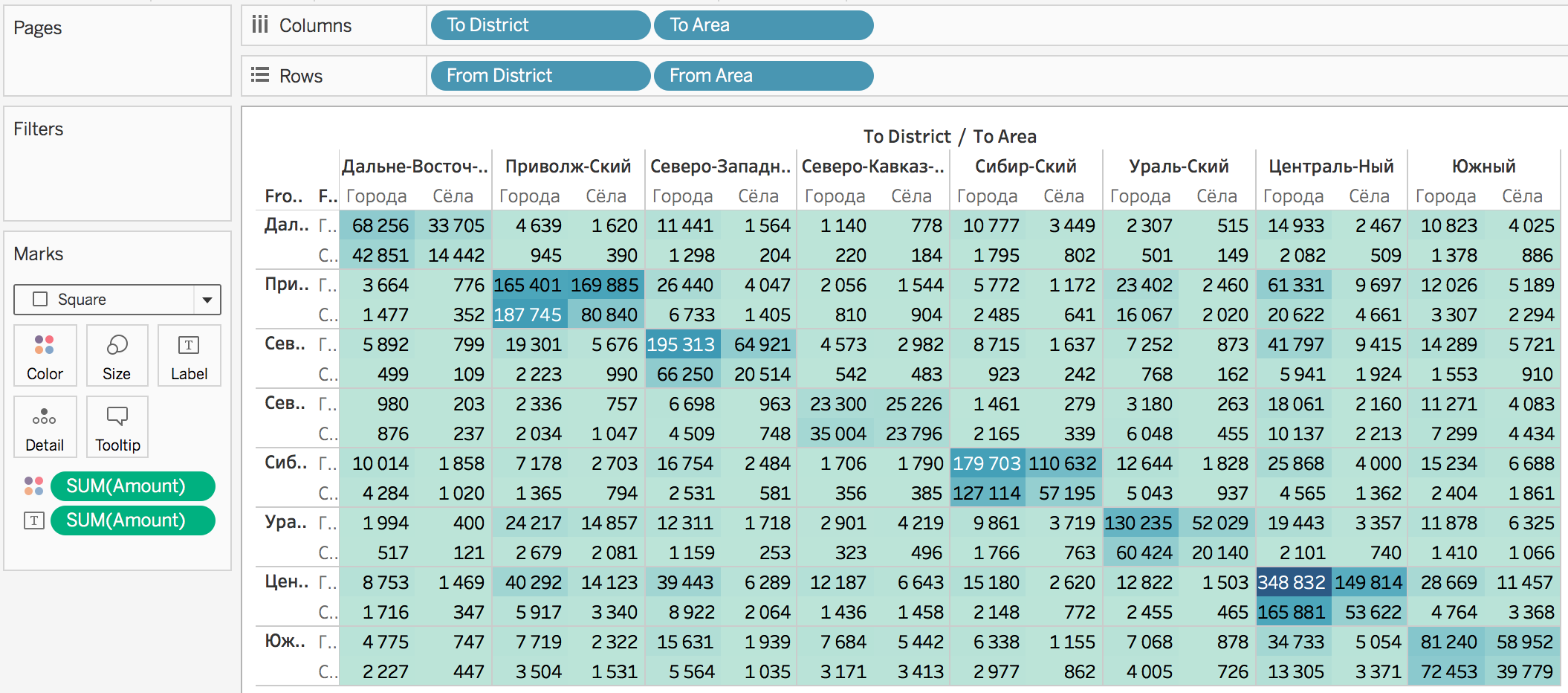
В диагональных ячейках, вероятно, показано, сколько человек переехало внутри своего ФО, оставаясь в городской или сельской местности. То есть, из города в другой город, или из села в другое село.
Уберём переезды внутри своего ФО, чтобы внимательнее рассмотреть остальные:
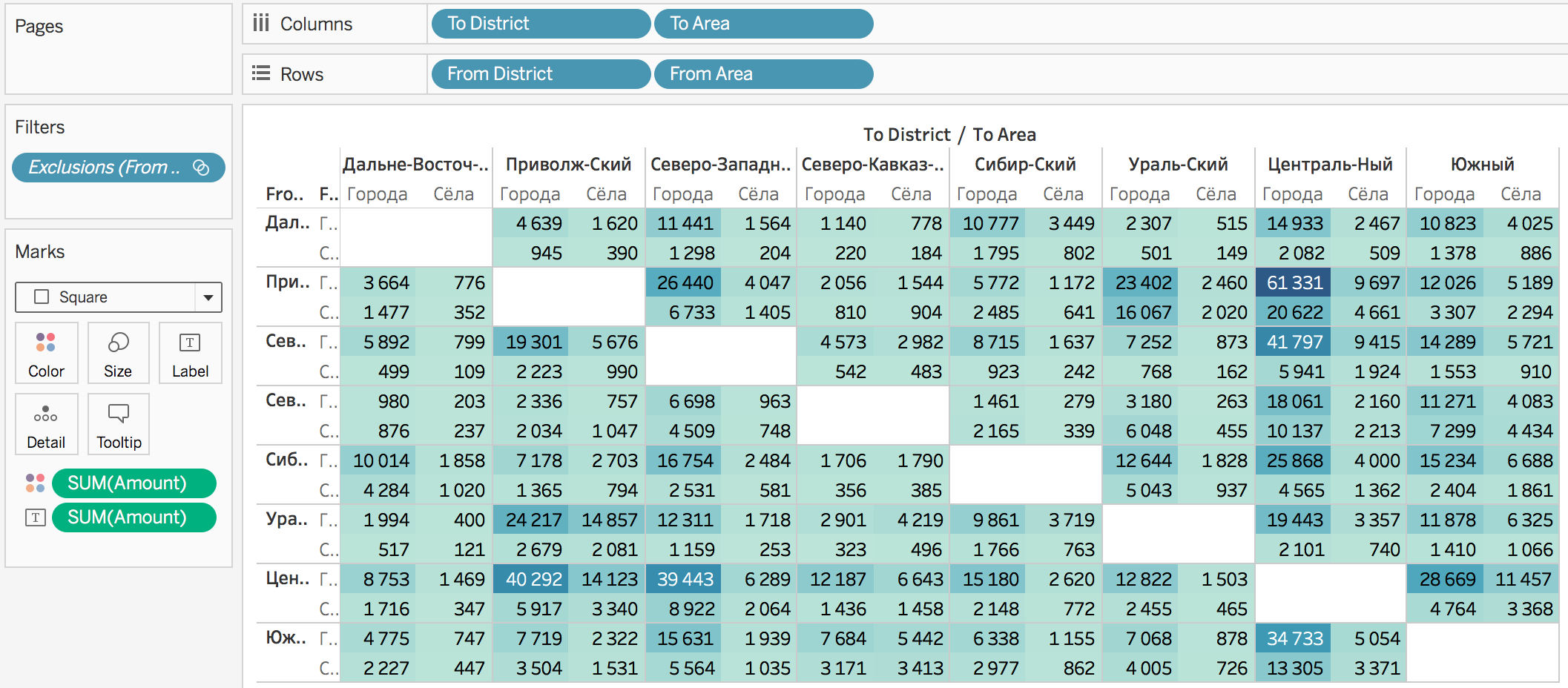
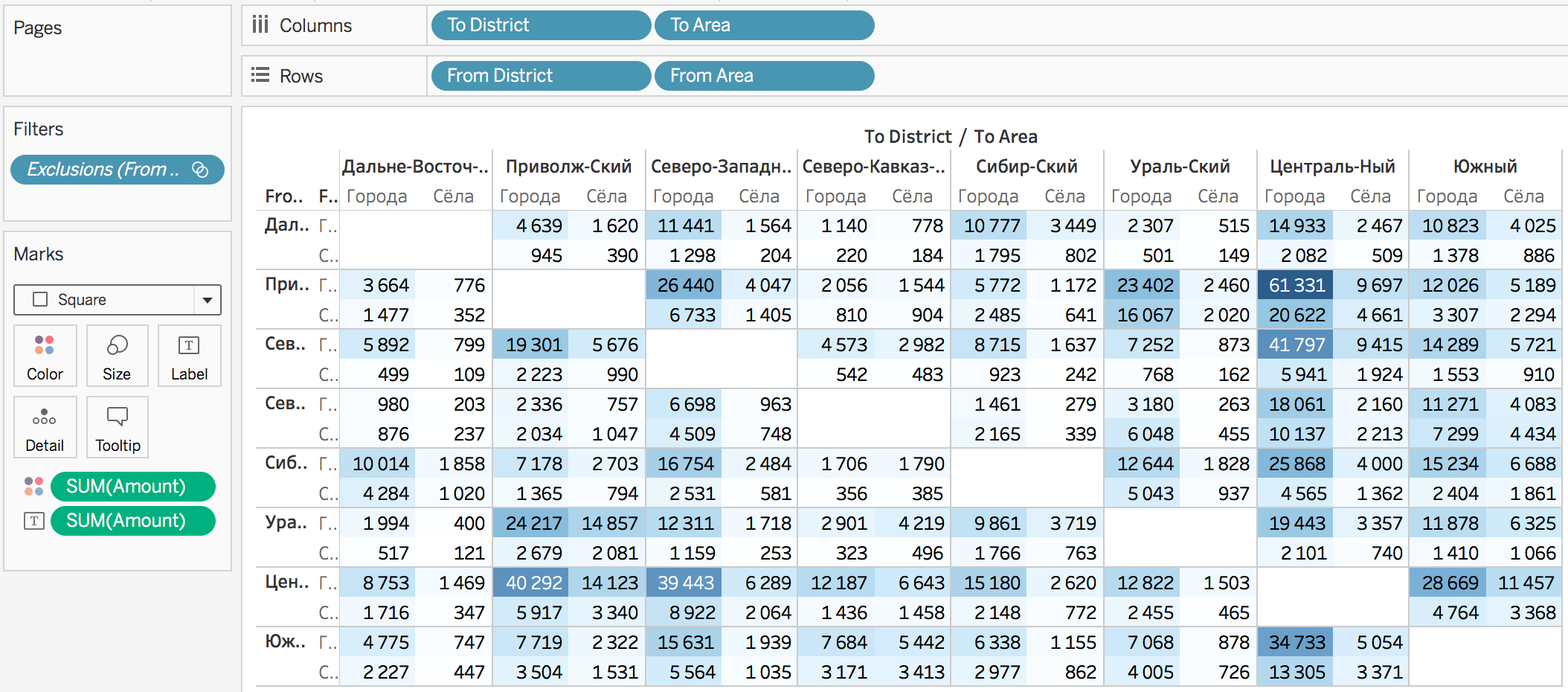
Чтобы цветовая палитра была ближе к действительности, лучше сдвинуть так, чтобы нулевые значения были белыми. Тогда число в ячейке будет пропорционально количеству синей краски:
В данных Росстата есть информация за несколько лет, почему бы не показать динамику изменения миграции? Перевожу остаток данных Росстата в нужный формат при помощи Vim и Табло, рисую гарфики:
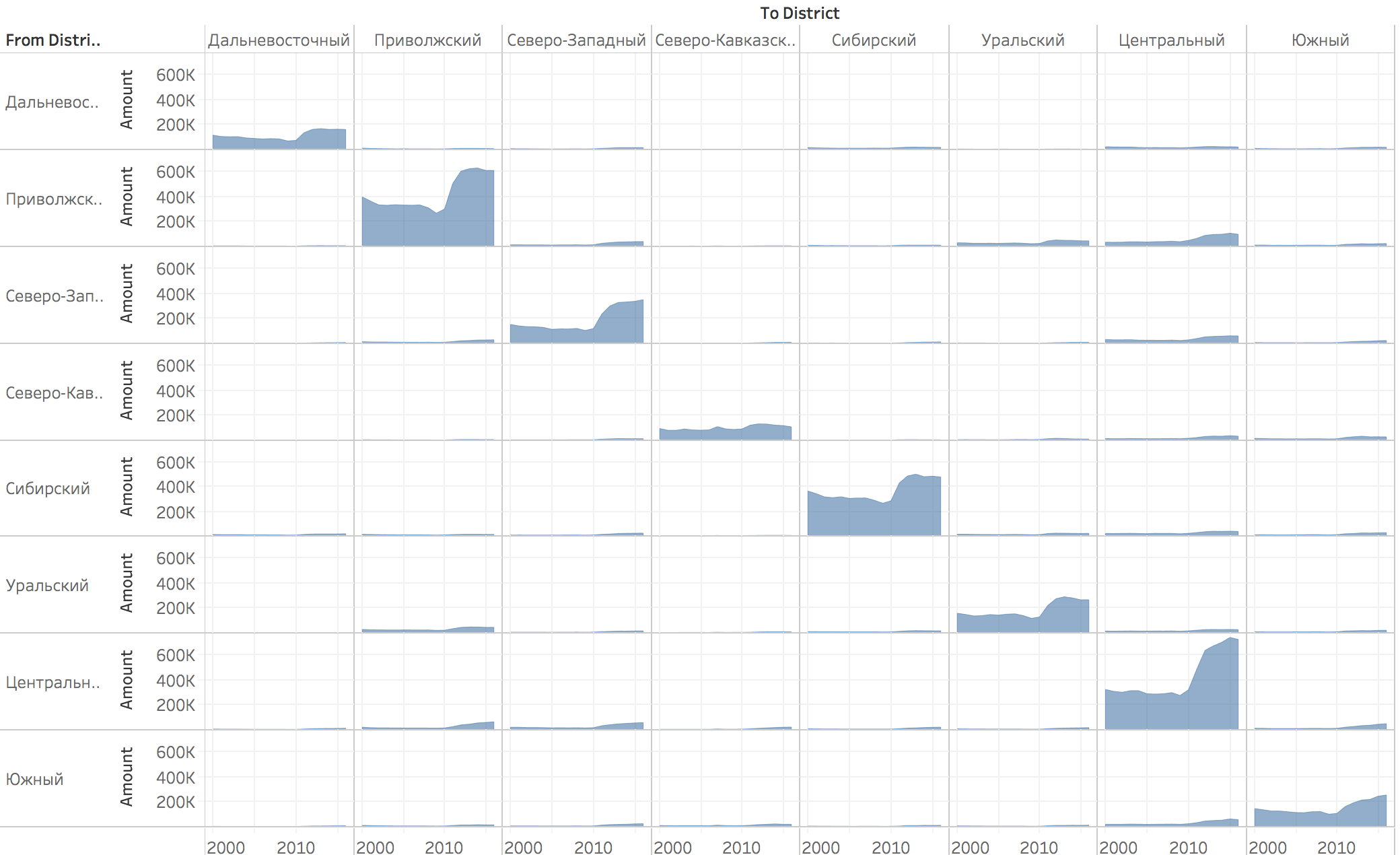
Площадь графика показывает число переездов за все годы. Видим, что в 11 году все дружно начали переезжать
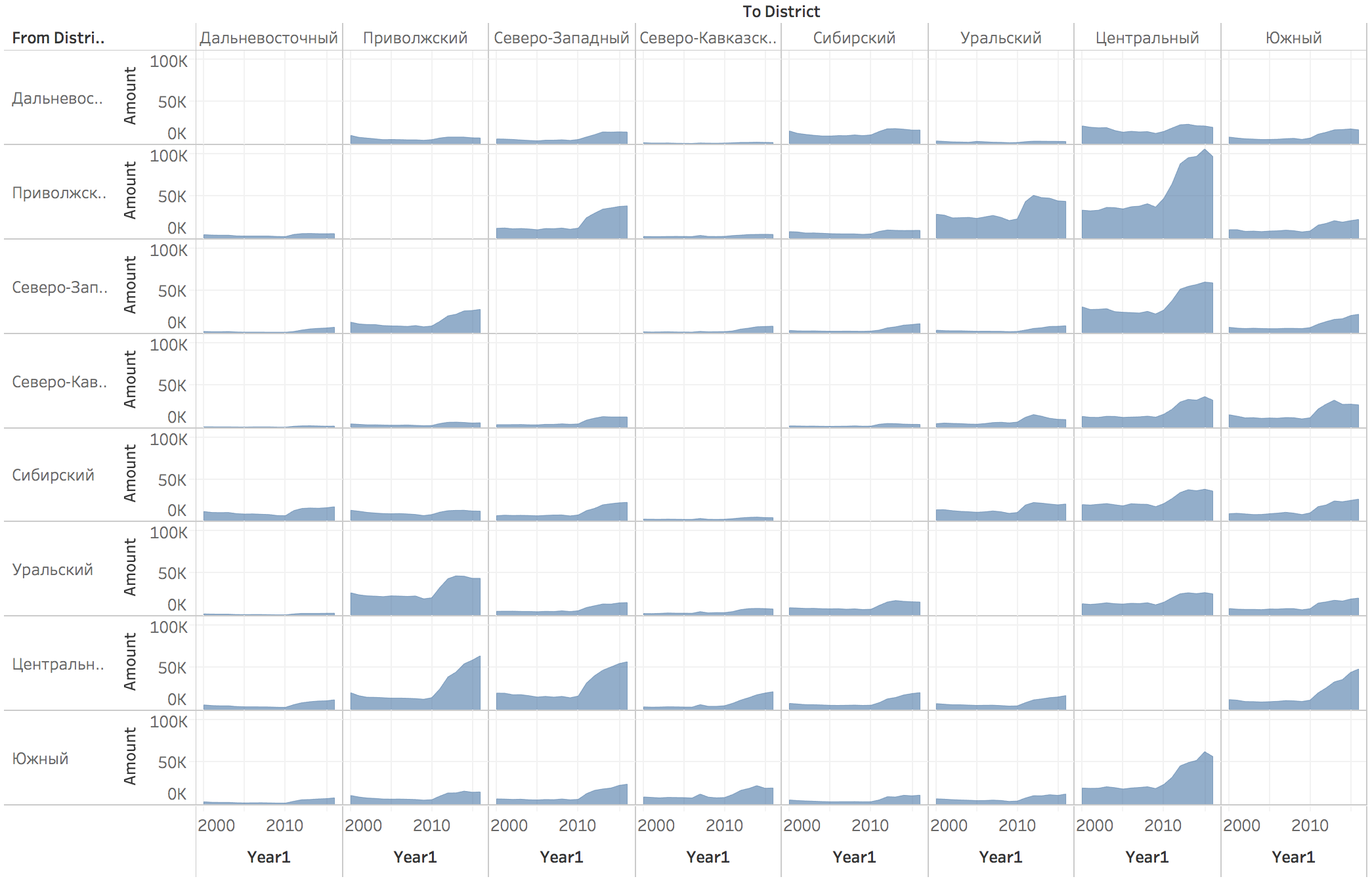
Если оставить только переезды в другие регионы, будет так
Между делом показываю результат Роме Бунину, он предлагает попробовать санки чарт. И показать всё-таки карту России. Пробую санки:

Справа порядок неправильный, не стал пока исправлять
Слева — сколько уехало из округа, справа — сколько приехало. Клёво, что все потоки видны и что они похожи именно на потоки. Если с таблицей надо разбираться, тут сразу видно, что что-то куда-то перетекает. А если не повторять каждый регион по два раза? Пробую вариант с chord diagram, которую собираю в онлайн-генераторе:
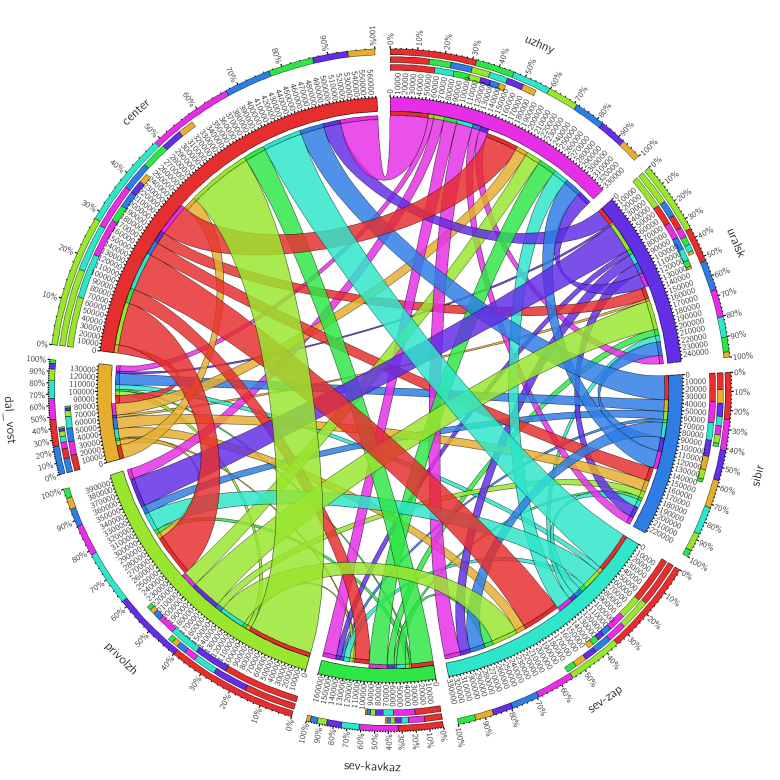
Даже если не обращать внимания на весь обвес, стало слишком сложно. В середине каша. А ещё в подобных диаграммах потоки в середине становятся тоньше. Такое решение улучшает читаемость, но искажает данные.
Тупик. Запоздало иду искать аналогичные визуализации.
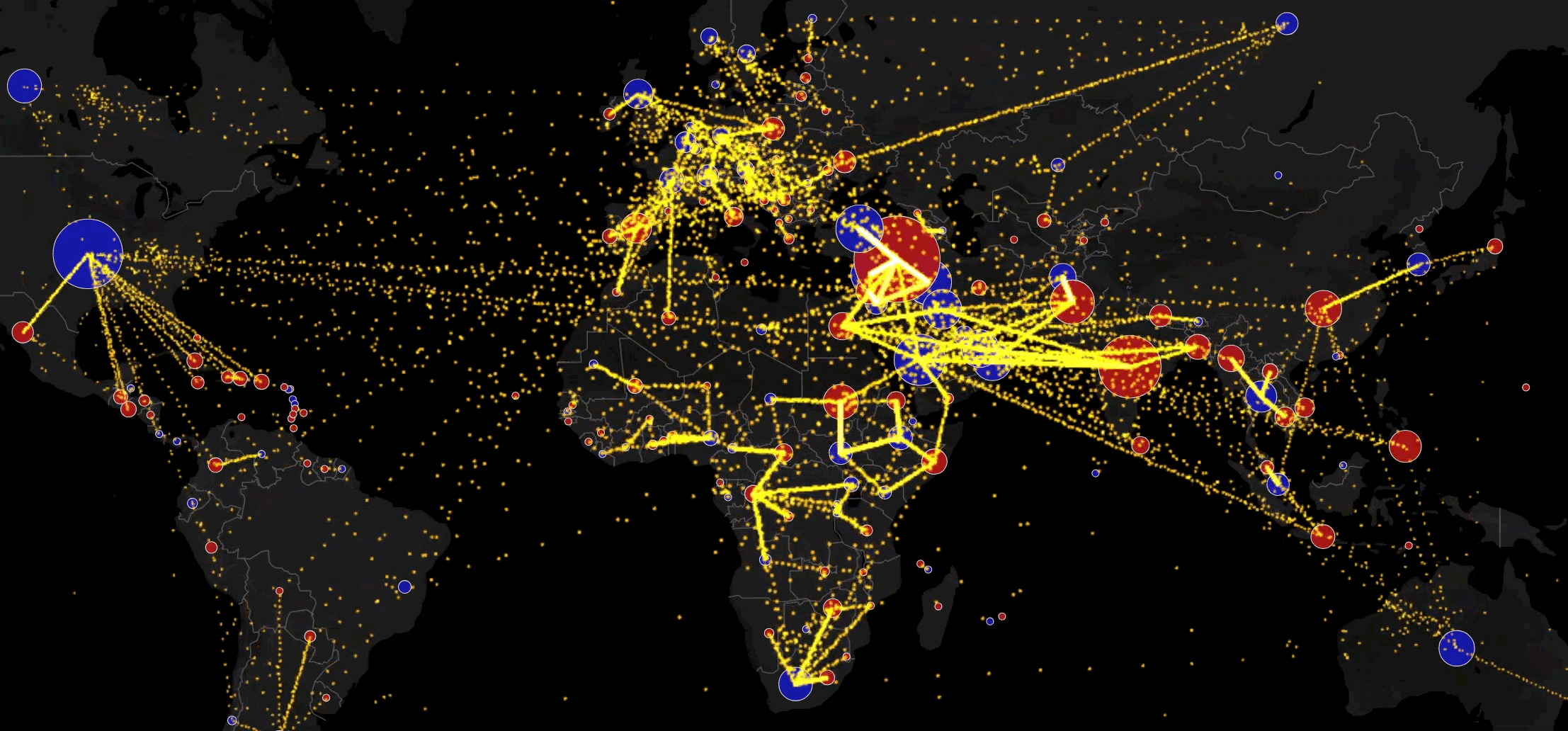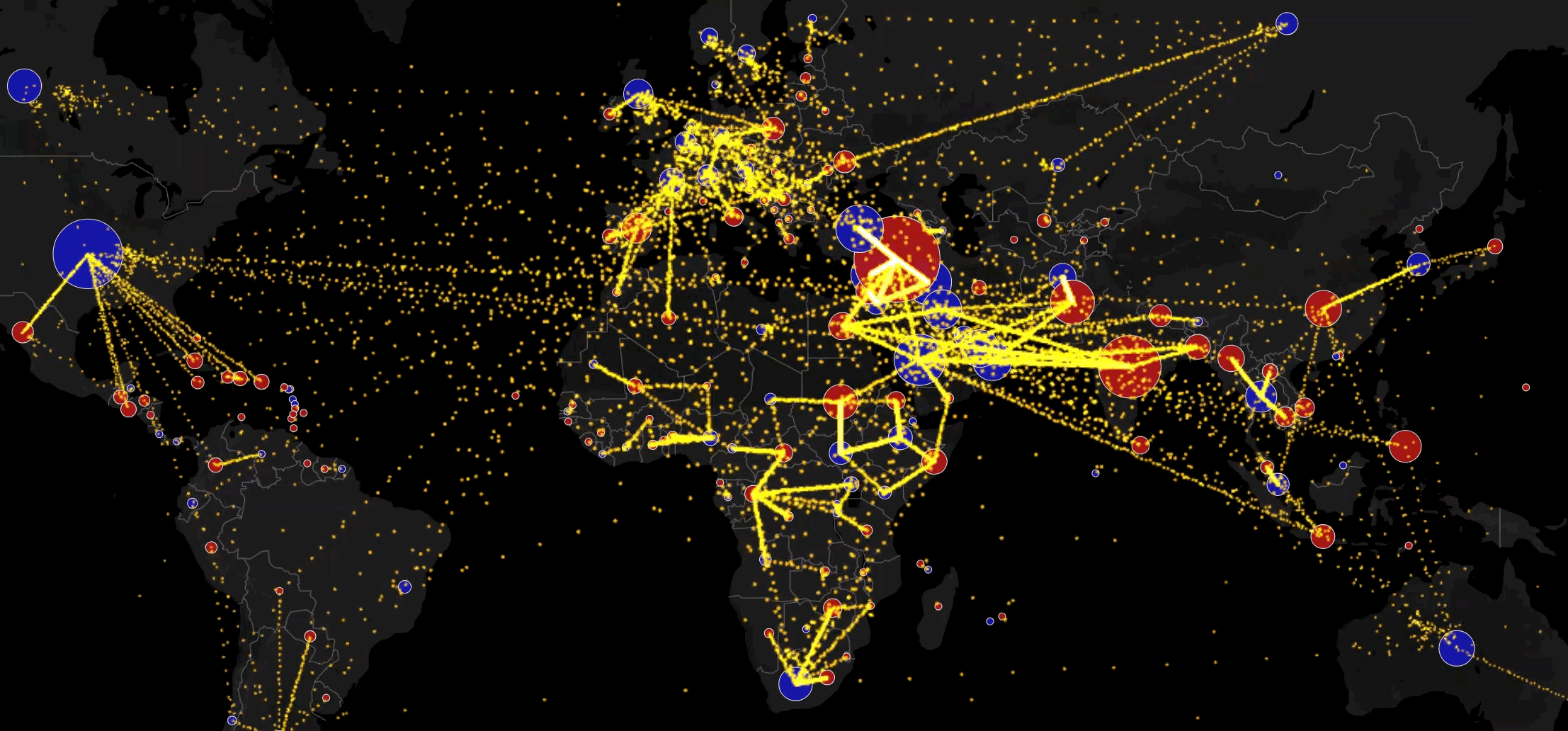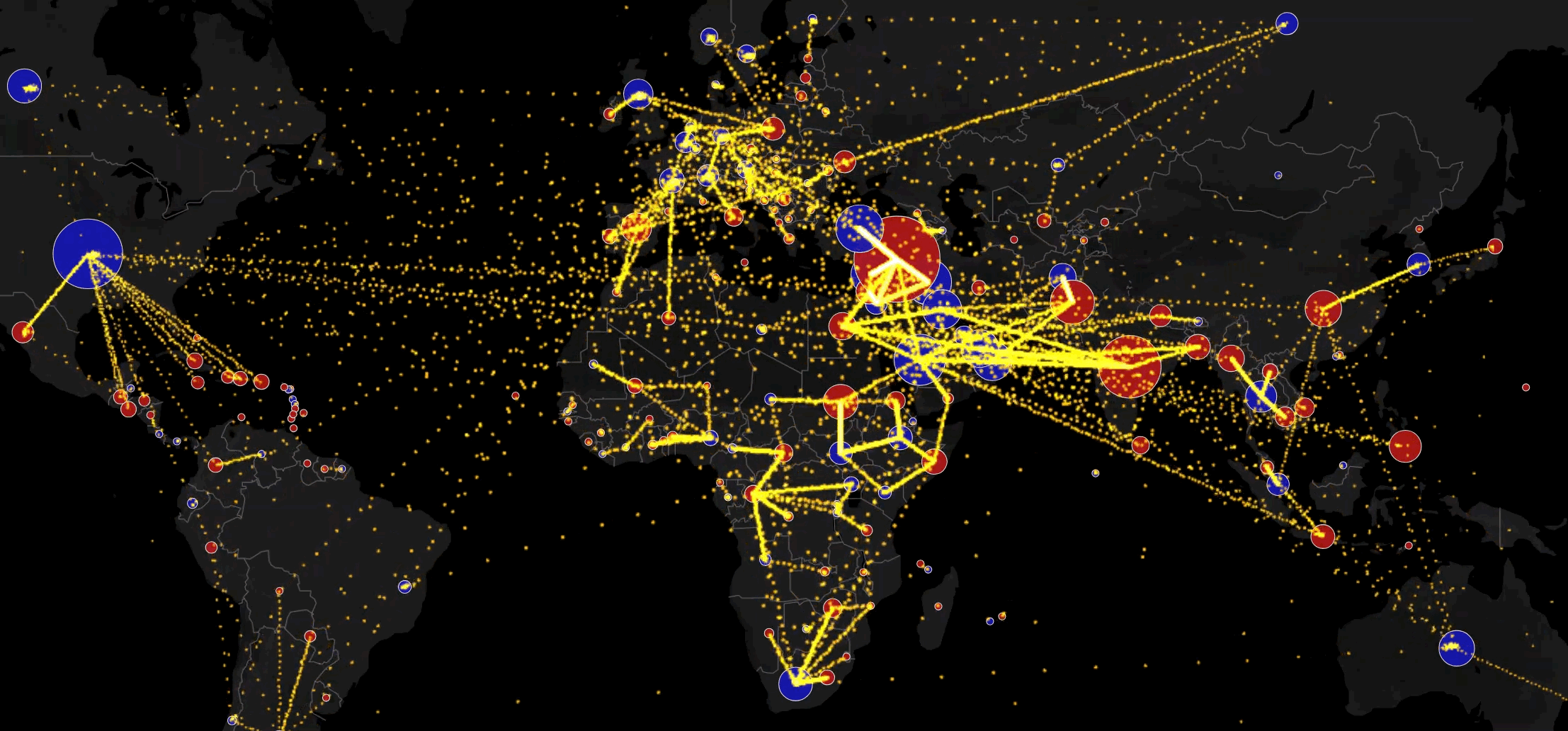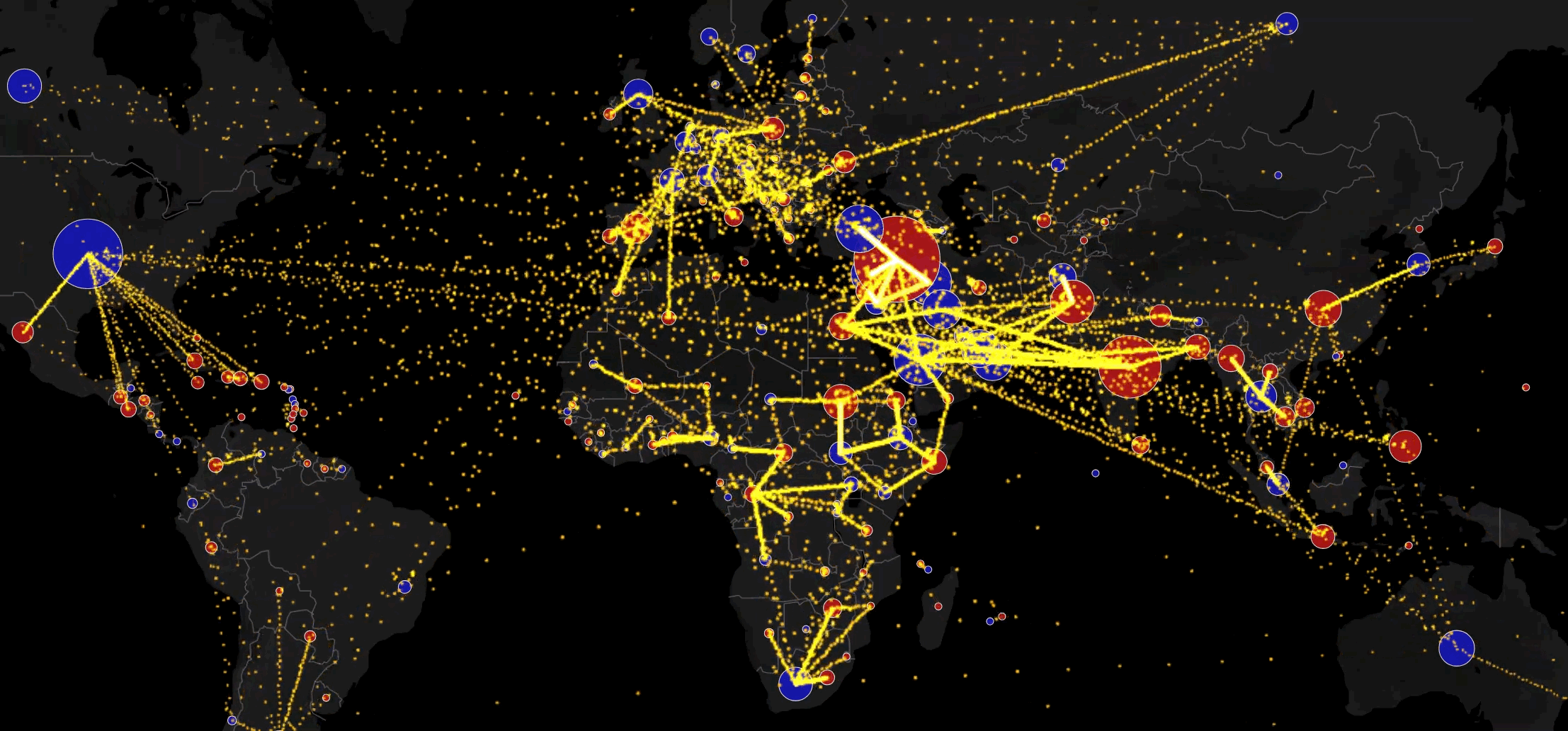
Красиво, но если показать миграции между всеми штатами, будет каша
Плюс много санки и chord:
Делаю десяток набросков, в голову приходит странный вариант: а что, если сделать аналог плиточной карты для округов? Прототипирую в табло:
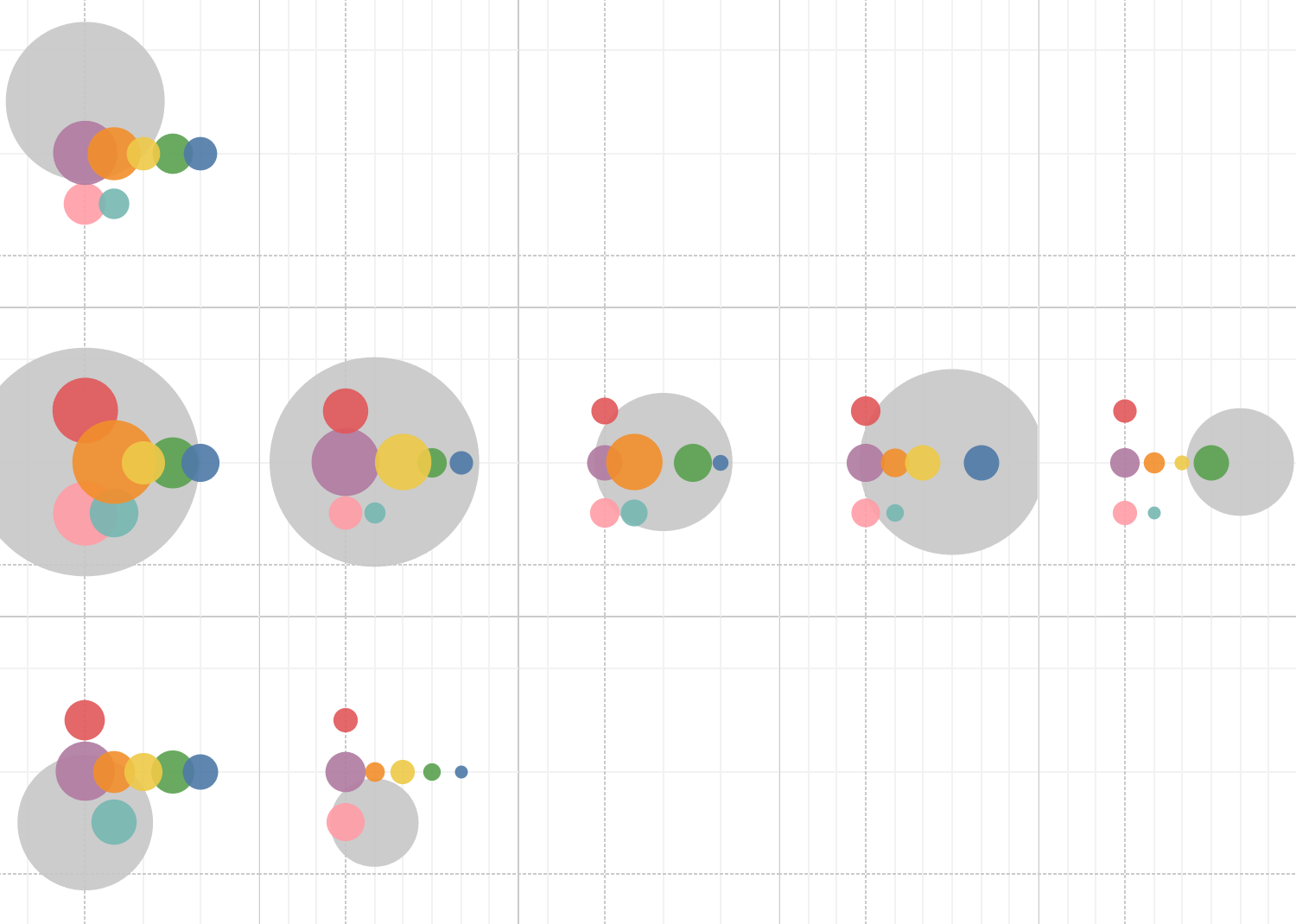
«Карта» состоит из восьми клеток-округов. Внутри каждого округа — такая же карта округов. Чтобы узнать, из какого округа чаще всего переезжают в ЦФО, надо выбрать в клетке ЦФО самый большой кружок. И посмотреть, какой округ он означает. Переезды внутри региона показываю серыми кружками.
Экспортирую из Табло ПДФ и допиливаю в Скетче:
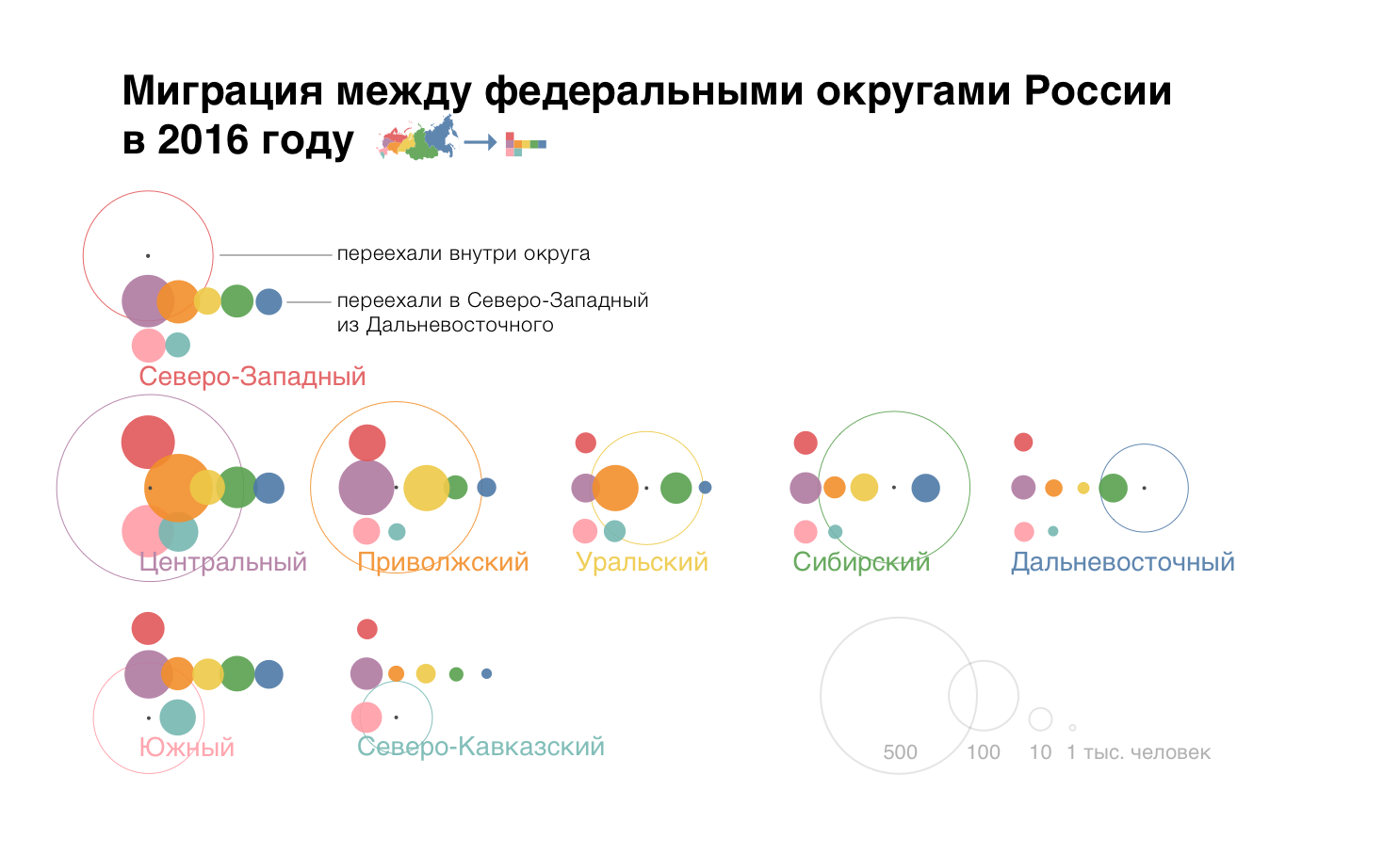
Показываю Андрею Ересу. Оказывается, ничего не понятно, надо было раньше показать :–\
Решаю вернуться к старой версии с таблицей. Пробую импортнуть ПДФ из Табло в Скетч, но всё очень тормозит. Поэтому визуализирую на d3, дорабатываю в Скетче:

Доработать не успеваю, решаю на этом закончить. Клёво было бы ещё показать численность населения округов и её прирост.
Перевёрстка тарифов 246 маршрутки
Мы тут с Андреем Ересом пробуем вести канал в телеграме. Перевёрстываем разные штуки, постим результат и процесс.
На этой неделе улучшали красоту:

Никогда не понимал таких бумажек. Сколько, например, стоит проехать от ПМК до Новенького? В каком порядке идут остановки? Попробовал сменить формат. Процесс:
Результат:

Сразу видно, что от ПМК до Новенького цена не предусмотрена, надо торговаться с водителем. Но в любом случае, не дороже 33 ₽.
Опубликовал в телеграме а потом понял, что полосочки можно ещё плотнее утрясти:

У такого варианта большой косяк: чтобы убедиться в правильности цены, надо весь лист обежать глазами. Тут надо помнить, что лист висит на стене и пальцем по нему водить не всегда получится. Например, чтобы узнать стоимость проезда от Современника до Средней Ахтубы, надо глазами проделать вот такой путь:

Чтобы решить эту проблему, нарисовал вариант с дугами:

Пожалуй, так лучше. Глаз быстрее находит линию, соединяющую две нужные остановки.
Пробую вариант с треугольной таблицей. Где не хватает цен — додумываю.

Но это, конечно, жесть: надо инструкцию рядом вешать, как цену определять. Чтобы сделать формат понятнее, придётся дублировать информацию. Раз уж у нас в итоге получилась скучная таблица, добавим немного визуализации:
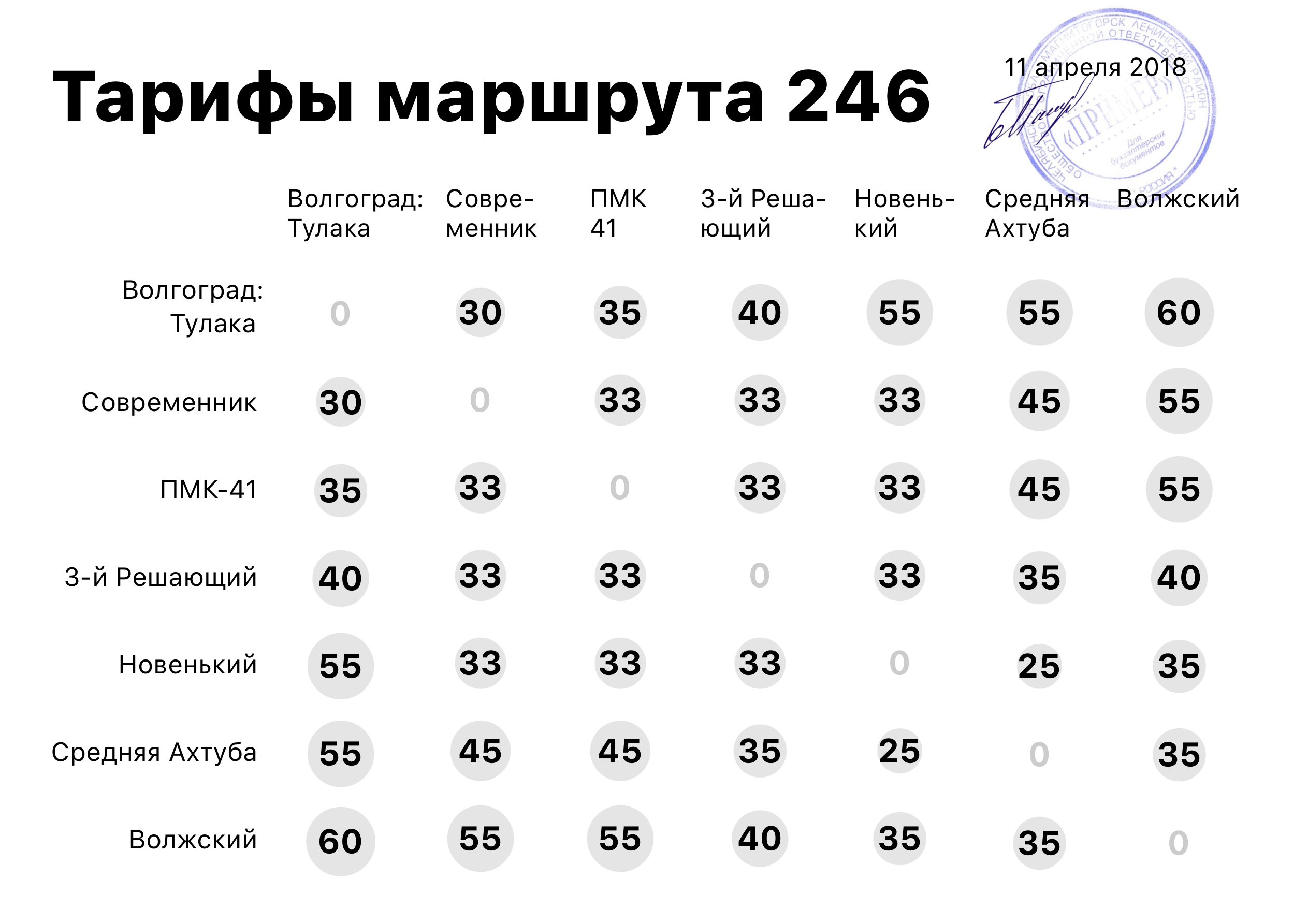
Знаете, как сделать лучше? Присылайте свой вариант мне в телеграм: @ivan_dianov. Опубликуем и прокомментируем его в канале «Перевёрстка».
Как я конспектирую оффлайновые лекции
Алексей Белицкий спрашивает:
как ты делал заметки на курсе? я скачал симплнот, но не вижу как загружать туда фотографии. Когда поеду на профсоюкс тоже хочу все законспектировать. У тебя получились очень хорошие подробные заметки
Текст набираю в формате Markdown в редакторе Vim, но подойдёт любой другой с подсветкой синтаксиса. Можно сразу писать в Simplenote.
Фотографирую на телефон, в конспекте тут же отмечаю текущее время, вот так:
(15:52)
Эти отметки помогают потом найти нужную фотографию. Дату снимка не пишу, если она понятна из контекста. Вечером прохожусь по отметкам и заменяю их на фотографии.
Фотографии для этого загружаю на Amazon S3 или в комментарии в Github Issues. Гитхаб даёт маркдаун-код для вставки в конспект, удобно:
Думаю, есть способы и попроще. А как вы ведёте конспекты?
Скриншоты в текст
Когда нужно распознать текст скриншота, открываю сервис http://www.free-ocr.com/. От сотни подобных он отличается возможностью вставить картинку из буфера обмена.
Распознаёт с ошибками, но иногда их исправить быстрее, чем вбивать текст с нуля.
Как запомнить нумерацию месяцев
Придумал себе запоминалку: номера первых месяцев сезона делятся на 3:
- 3 — март,
- 6 — июнь,
- 9 — сентябрь,
- 12 — декабрь.
Номера остальных месяцев после этого тоже легко запоминаются. Октябрь идёт за сентябрём, значит десятый, и так далее.
Идеальное согласование макета
Однажды я за четверть часа согласовал правки по макету сразу с восемью представителями заказчика — муниципальной организации.
Сперва думал, что работу не закончу никогда: буду показывать новые версии, получать пакеты правок, и так в бесконечном цикле. Сложнее всего было договориться о расположении 15 информационных блоков: каждый участник обсуждения хотел расставить их по-своему.
Помог такой приём: я распечатал макет, порезал его ножницами, отдал толпе и отошёл в сторонку. Они бурно спорили между собой, перекладывали листики, а потом вдруг пришли к консенсусу. Я уточнил, все ли согласны, и торжественно сфотографировал бумажки. Сделал по этой фотографии макет и его сразу приняли.
До сих пор вспоминать приятно.
Плиточная карта России
Коллега прислал ссылку на конкурс со странным названием. Нужно придумать, как разделить Россию на квадратики, чтобы делать клёвые плиточные визуализации. У Америки такая есть:
Все штаты-квадратики одного размера, поэтому их данные легко сравнить между собой
Для России такую карту сделать сложнее, потому что её субъекты сильно отличаются размерами:
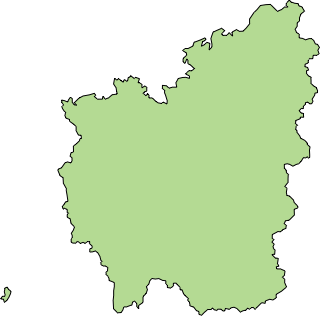
Чтобы прочувствовать проблему, сравните Ингушетию с Сахой
Кажется, квадратами нарисовать Россию невозможно. Решаю «приблизиться к оленю» и пробую шестиугольную сетку. Рисую графики похожие на настоящие. Придумываю, как сократить названия регионов. Выходит так:

Я ничего не потеряю, если сделаю тайлы квадратными. График тогда можно увеличить а рамку удалить:

Оу, теперь можно сдвинуть колонки на полвысоты и получить нормальную квадратную карту. Это круто: ячейки выстраиваются в горизонтальные линии и данные проще сравнивать.

Показываю Роме Бунину, ведущему курса о визуализации данных. Кстати, курс стартует 8 декабря в Москве, приходите. Можно удалённо.
Рома недоволен:
Чтобы сделать карту ближе к России, пробую равномерно надуть восток:

Чтобы хоть как-то уплотнить карту, убираю горизонтальные отступы:

Вышла расчёска :–( Никто не догадается, почему одни регионы рядом а другие далеко. Может разрешить карте быть дырявой? Нет, станет ещё непонятнее.
Пробую гигантские субъекты нарисовать гигантскими:

Мало надул, не похоже на Россию. Дуем дальше:

Форма похожая, но теперь понятно: нельзя к каким-то двум регионам привлекать столько внимания. Поэтому распиливаю страну по Уралу и показываю европейскую часть крупно. Так в некоторых проектах делает Лаборатория Данных:
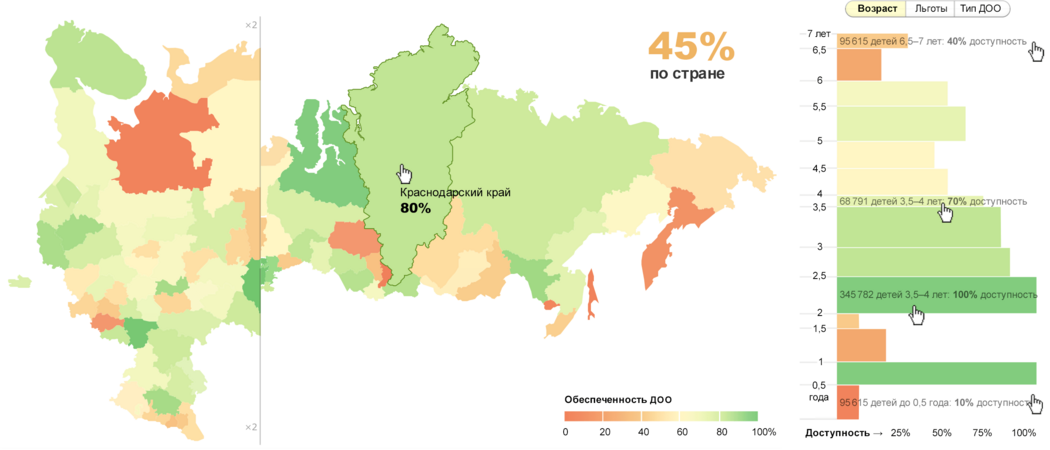
Получается так:

С Сибирью беда. Ямало-Ненецкий и Ханты-Мансийский округа отвалились от Ненецкого. Свердловская область почему-то на севере. Надо ближе половинки сдвинуть, а то непонятно, что это одна страна.

Нравится, что строки востока и запада не совпадают, это усиливает ощущение разреза. Показываю Роме, он одобряет:
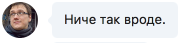
На радостях рисую римейк карты с флагами.
{kind=link}

У Сахалина флаг крутой
В её форме не угадывается Россия, однако, рассматривать интересно. С названиями было бы круче, но уже лень.
Чтобы оценить, точность плиточной карты, раскрашиваю её колонки в разные цвета, так же крашу исходную карту:
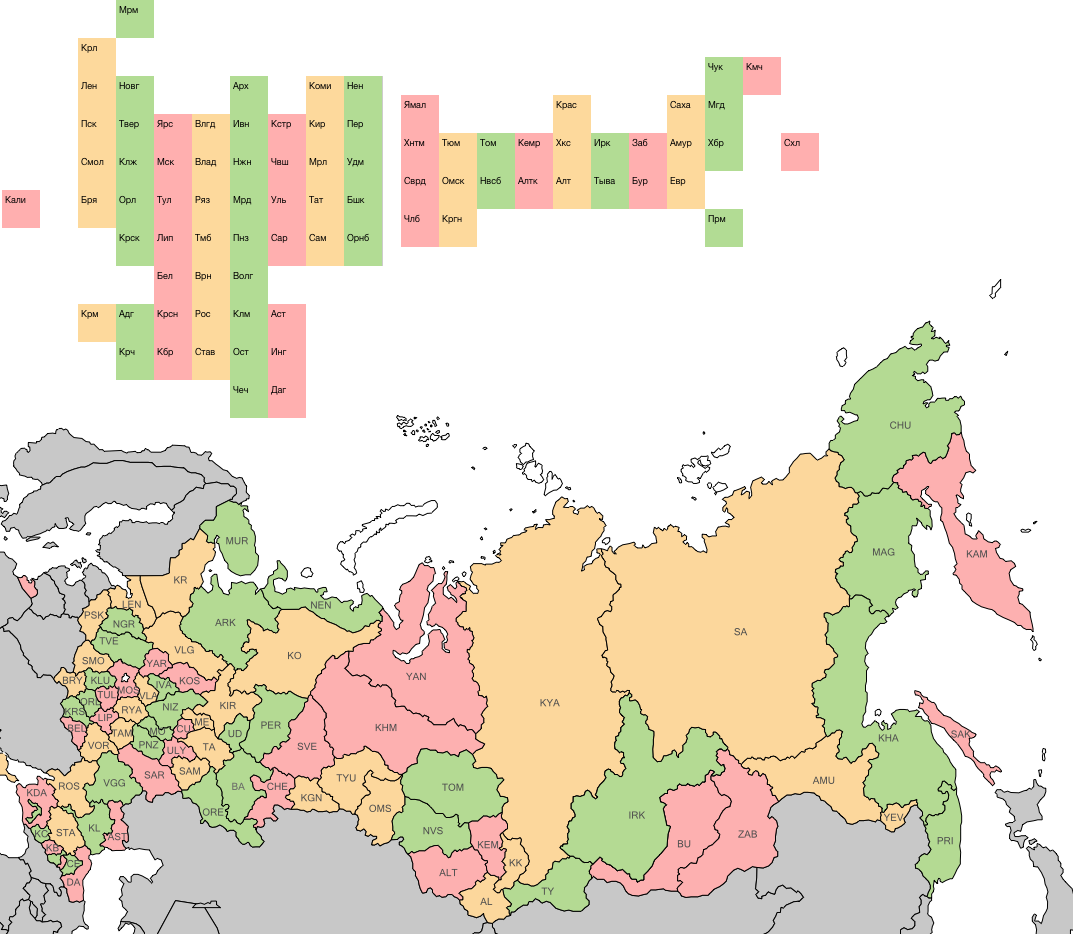
Жесть. На Кавказе всё перемешалось: Кабардино-Балкария прилипла к Краснодару, хотя надо было прилипить Карачаево-Черкесию. Ингушетия граничит с Астраханью и Дагестаном, а с Чечнёй — нет. На северо-западе тоже плохо. Надо всё выравнивать заново.
Выравниваю, выравниваю, выравниваю. Не выравнивается. Стоит исправить один косяк, вылезают два других.
А-а-а-а-а-а! Россия кривая!
(╯°□°)╯︵ ┻━┻
Запоздало придумываю принципы:
- Приграничные субъекты лучше рисовать по краям, остальные — в серединке.
- Чем больше сохранится правильных границ между регионами, тем лучше.
- Особенно важна аккуратность в Центральном федеральном округе.
- Федеральные округа не должны рассыпаться.
- Форма карты должна хотя бы отдалённо напоминать Россию.
Ещё надо по-другому сократить названия субъектов. Никто не догадается, что «Мрл» — республика Марий Эл. Назваю регионы их первыми буквами, короткие названия пишу полностью. Тут тоже не без сюрпризов. Как сократить Краснодар и Красноярск? «Крас» и «Крас»? Решаю иногда делать исключения.
В английской верии с сокращениями регионов будет дико проще, есть официальные.
Снова всё двигаю. Выходит лучше:
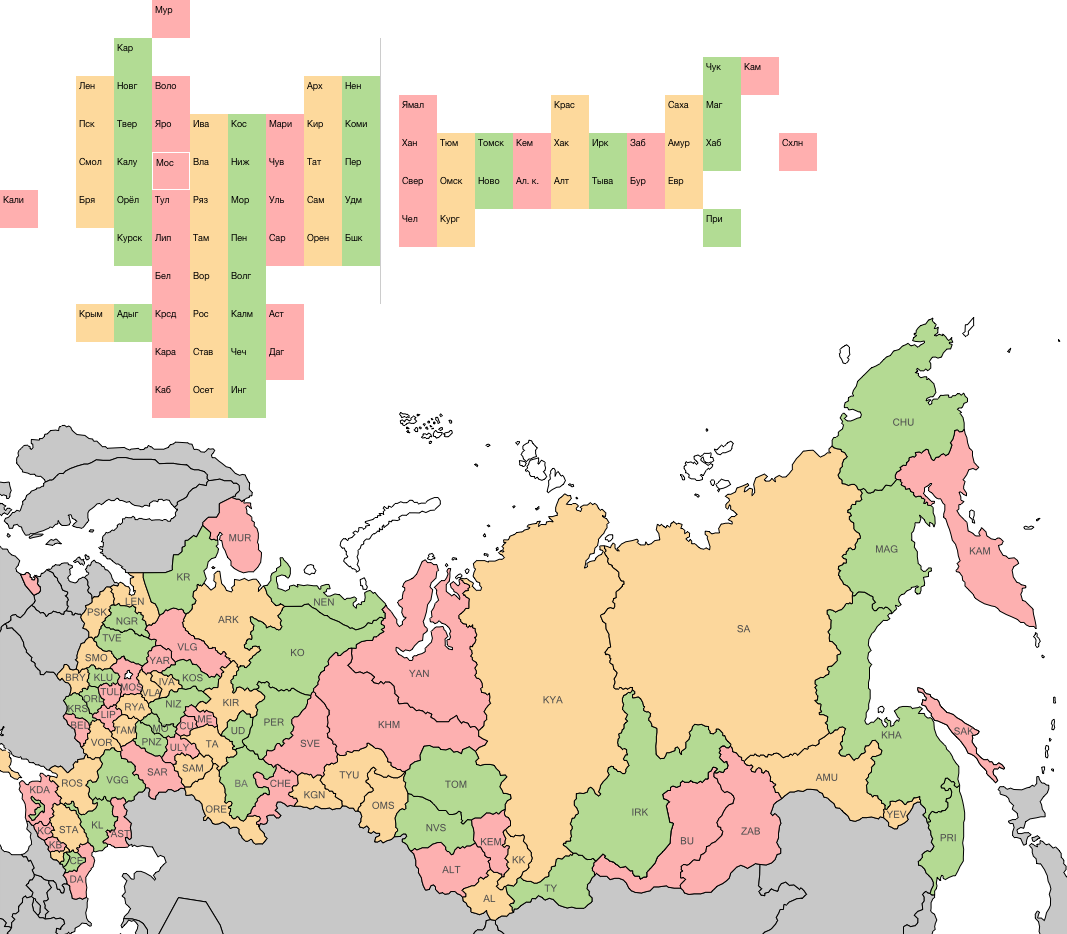
Рисую горизонтальные полоски:
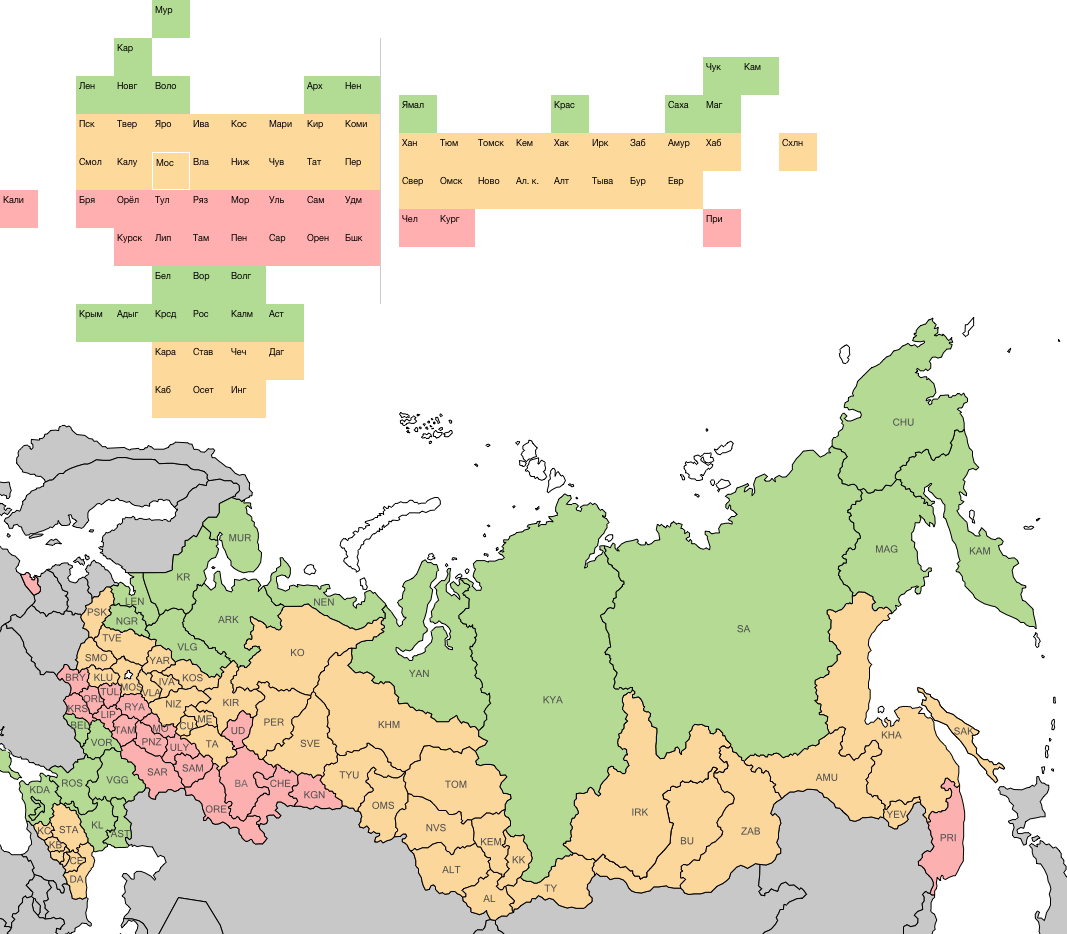
Стало чуть менее криво. Проверяю, не развалились ли округа:

Северо-Западный федеральный округ порвался, ну и пускай.
Придумал более наглядный способ оценки качества карты. У каждого квадратика от 0 до 4 соседей. Обозначу эти соседские отношения линиями на исходной карте и получу сетку четырёхугольников. Чем ровнее сетка, тем лучше карта.
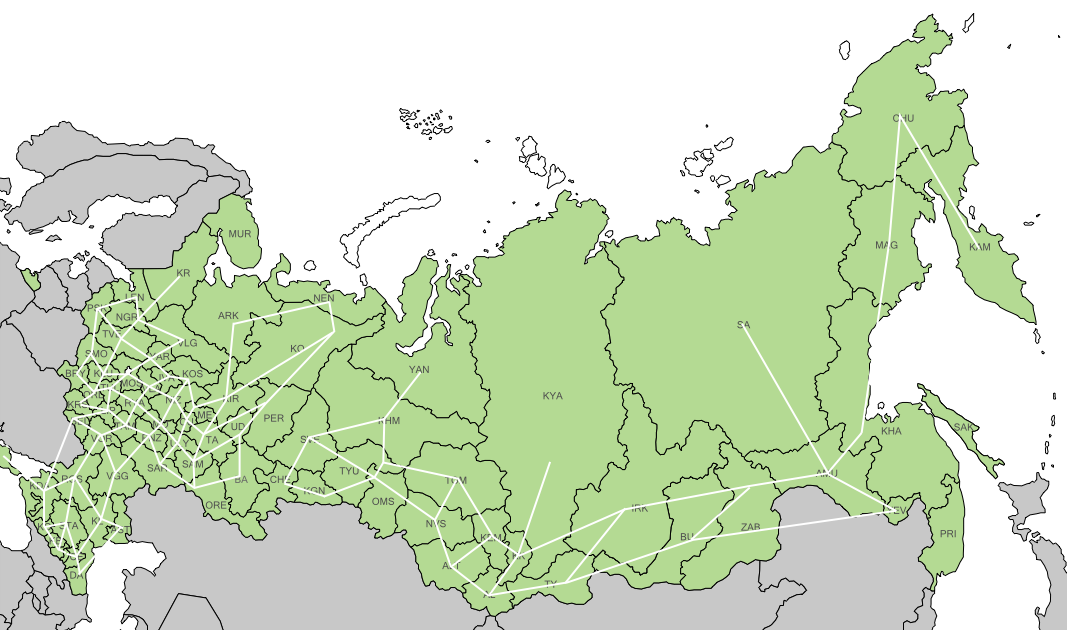
Сразу видно, что западный Урал задрался наверх.
Другая проблема: восточная часть по форме не похожа на Россию. Исправляю:
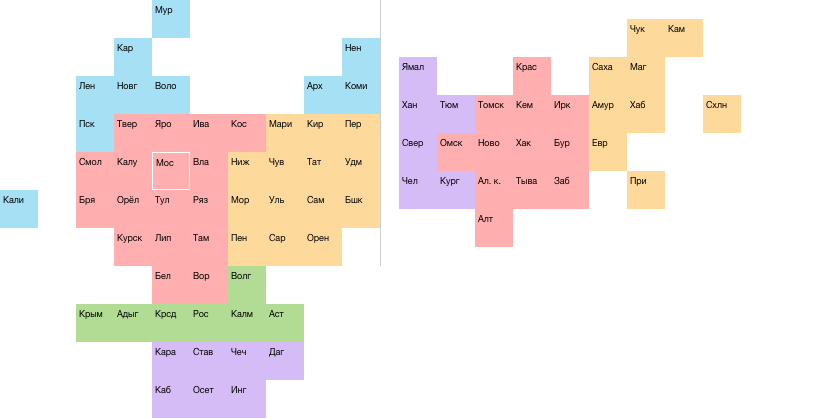
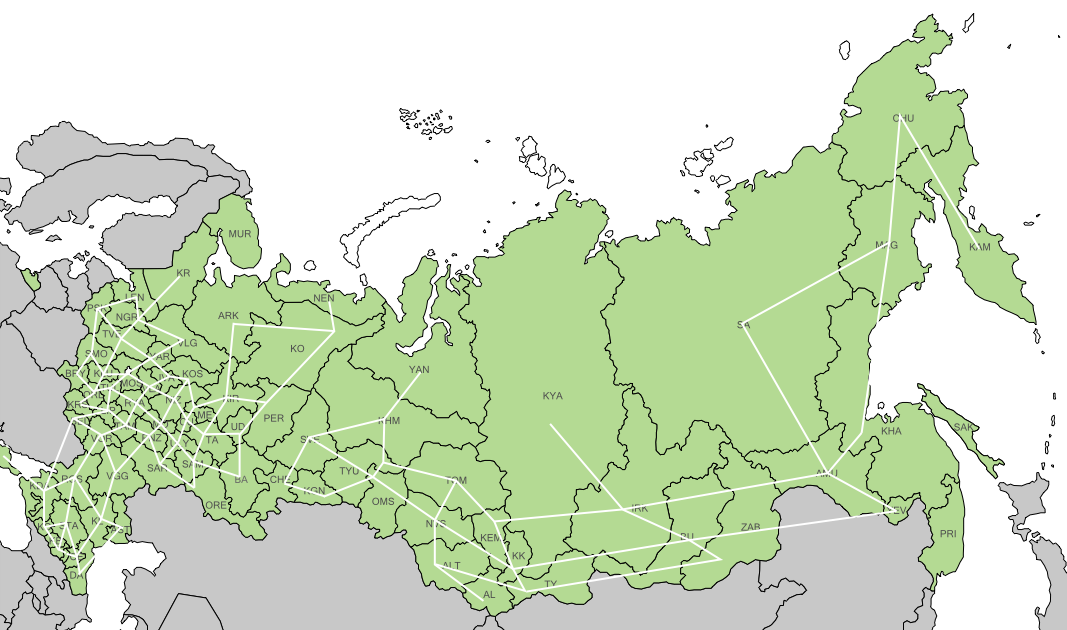
Запад стал лучше. Квадратик Оренбурга ушёл вниз, Ненецкий округ — наверх, проверочная сетка выровнялась.
На востоке сетка ухудшилась. Алтай и Алтайский край уехали от Кемерово, а Бурятия присоседилась к Еврейскому АО. Но я на это согласен, потому что форма страны стала узнаваемой. Алтай вывалился вниз, как на настоящей карте, и стал дополнительным ориентиром.
Хуже всего то, что Омск между Свердловской областью, Тюменью и Курганом. Хотя на самом деле он восточнее этой тройки. Пробую поменять его местами с Курганом.

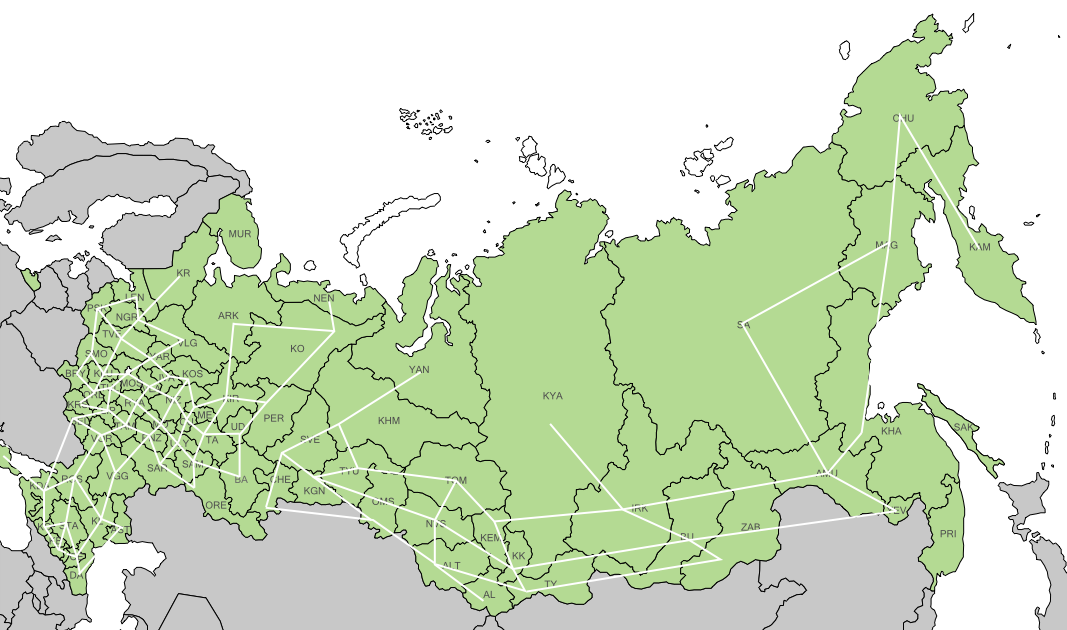
Проверочная сетка разъехалась в районе Омска в тартарары, но зато федеральные округа «расцепились», находить нужные субъекты стало проще.
Если квадратики карты на визуализации залиты полностью, можно сдвинуть половинки карты поближе:

Если нет заливки, то лучше оставить линию на месте Урала:

Готово :–)
Следующий этап — что-нибудь визуализировать. Например, число аварий на дорогах.
Список списков ресурсов для айтишников
Я недавно писал про пользу изучения списков.
На Гитхабе лежит очень крутой список списков. В основном всё про разработку и айти. Мне понравились такие:
- про визуализацию данных: фреймворки, библиотеки, приложения
- про визуальное тестирование
- про дизайн интерфейсов
- про здоровье: приложения, библиотеки, инструменты, ресурсы