Как сделать из своего имени поплавок
В Парке Интуиции мы с ребятами сделали маленький клёвый проект. Не спрашивайте, зачем он этому миру. Давайте считать, что это не сервис, а искусство.
Флотерея берёт любое имя и — шмяк! Делает из него поплавок. Наконец-то вы сможете больше узнать о себе и своих друзьях
Женя Арутюнов предложил написать про его устройство:
Сколько там переменных, как они связаны, как влияют на форму. Что такое грамматика, какая она. Как из текста получается набор переменных. Как устроены все интеграции, как был устроен процесс совместной разработки.
Вкратце
Поплавки собираются из заранее нарисованных секций. Не как попало, а в соответствии с правилами, описанными порождающей грамматикой. Она определяет разные варианты поплавков: какие в них типы секций, и в каком порядке они идут.
Последовательность получается рандомной, но эта рандомность зависит от содержимого текстового поля. Одинаковые значения будут рисовать одинаковые поплавки.
Входной СВГ файл
Поплавок собирается из секций, которые скрипт берёт из такого СВГ файла:
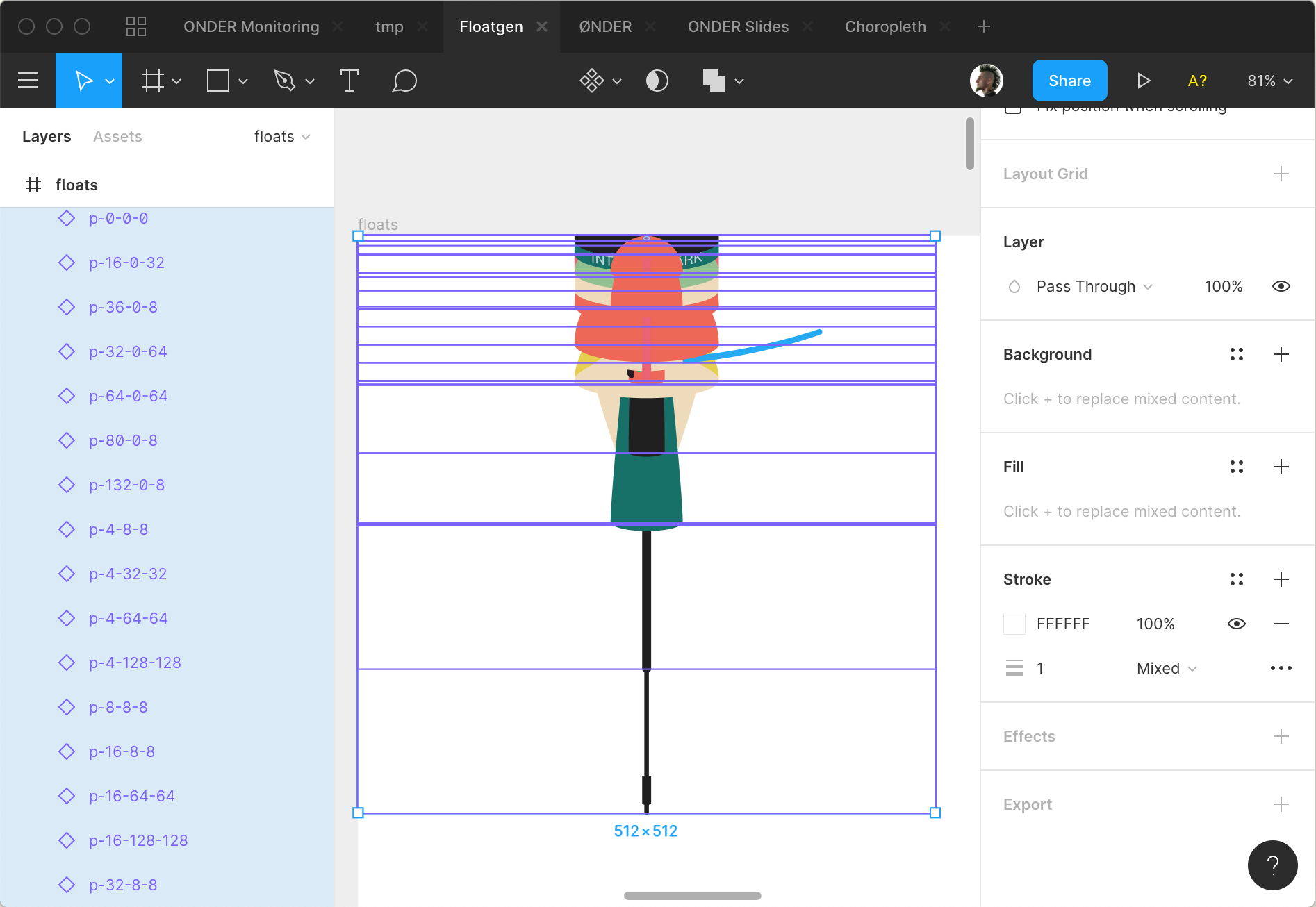
Все секции сдвинуты в верхний левый угол
Каждая секция лежит в своей группе.
Имена групп в формате p-16-32-100. Первая цифра означает высоту. Вторая — диаметр верхнего стыка. Третья — нижнего.
Порождающая грамматика
Это такая штука, которая может по заданным правилам создавать составлять последовательности слов. Вообще, грамматики нужны для генерации текстов, например, описаний монстров и титулов в играх. Но её можно использовать и не по прямому назначению. Например, ими генерят фракталы и космические корабли в СВГ.
Почему бы не использовать её для рисования поплавков? Каждая секция — как бы слово. И эти «слова» надо расставить в таком порядке, чтобы вышло грамматически правильное предложение — поплавок.
Для работы с грамматикой я выбрал библиотеку RiTa. Она понимает формат YAML.
Ниже покажу пример грамматики и расскажу, как она собирает поплавки из секций.
<start>:
- <type1>
- <type2>
- <type3>
- <type4>
<type1>:
- <0_8> <8_8> <8_8> <8_32> <water> <32_32> <32_8> <8_0>
<type2>:
- <0_8> <8_8> <8_8> <8_64> <water> <64_64> <64_8> <8_0>
<type3>:
- <0_8> <8_8> <8_8> <8_128> <water> <128_128> <128_8> <8_0>
<type4>:
- <dragonfly> <0_32> <water> <32_128> <128_8> <8_0>
<water>:
- <0_0>
Сокращённый, но по-прежнему рабочий пример поплавковой грамматики
В треугольных скобках токены — это такие штуки, которые могут превращаться в другие штуки. В примере ниже есть шесть секций, и в каждой из них говорится, чем тот или иной токен может стать. Если вариантов превращения несколько, они записываются один под другим.
В начале генерации есть единственный токен <start>, потом он в соответствии с правилами грамматики превращается в другие токены. Например, первое правило означает, что <start> может с равной вероятностью стать <type1>, <type2>, <type3> или в <type4>.
Допустим, мы получили из него токен <type1>. Посмотрим, во что может превратиться он:
<type1>:
- <0_8> <8_8> <8_8> <8_32> <water> <32_32> <32_8> <8_0>
Тут только один вариант. Зато какой длинный! Из токена неминуемо получается целая цепочка других токенов. Причём <water> в свою очередь неминуемо превратится в <0_0>. Потому что такое правило в грамматике тоже есть. И тогда последовательность токенов станет такой:
<0_8> <8_8> <8_8> <8_32> <0_0> <32_32> <32_8> <8_0>
Кажется, полученная последовательность токенов ни во что уже превратиться не может. Ведь в грамматике нет правил для превращения, скажем, <0_8>.
Но превращения ещё не закончены. Фокус в том, что некоторые правила грамматики создаются скриптом в зависимости от того, какие секции поплавков нашлись во входном СВГ файле.
Происходит этот так. Мы берём из входного СВГ все секции и запоминаем их в массиве. У каждого сегмента в массиве есть свой индекс, по которому его можно этот сегмент узнать и нарисовать на экране.
Для каждого сегмента мы добавляем в грамматику правило. Например, в массиве есть сегмент p-8-8-100 с индексом 2. Вспомним, что в названии секции первая цифра означает высоту, а последние две — верхний и нижний диаметры секций поплавка.
При его обработке в грамматику добавится правило:
<8_8>
- 2
То есть, секция поплавка с верхним радиусом 8 и нижним радиусом 8 может превратиться в секцию номер 2 из массива секций
Допустим, обработав все секции поплавков из входного СВГ, мы добавили такие правила:
<0_8>
- 0
- 1
<8_8>
- 2
- 3
<8_32>
- 4
<0_0>
- 5
<32_32>
- 6
<32_8>
- 7
<8_0>
- 8
Тогда наша строка
<0_8> <8_8> <8_8> <8_32> <0_0> <32_32> <32_8> <8_0>
может превратиться в
1 3 2 4 9 6 7 8
Поскольку некоторые токены, например <0_8>, имеют несколько вариантов превращения, итоговая последовательность может выйти немного другой.
Поздравляю! Мы получили последовательность индексов секций. Теперь остаётся вытащить секции с такими индексами из массива и нарисовать их одну под другой. И поплавок готов!
Делаем из имени поплавок
Когда в грамматике есть несколько вариантов превращений, один из них выбирается рандомно. Это обеспечивает многообразие возможных форм. Однако, чтобы одинаковые значения в текстовом поле создавали одинаковые поплавки, нам надо сделать эту рандомность зависимой от значения текстового поля. Библиотека RiTa может сделать рандомность предсказуемой:
RiTa.randomSeed(pseudoRandom);
Одинаковые значения pseudoRandom будут создавать одинаковые поплавки
На вход randomSeed() принимает число. А у нас в текстовом поле строка. Значит нам надо научиться из этой строки делать число. Нашёл для этого такую функцию на стековерфлоу, работает отлично:
function hashCode(str) {
return str.split('').reduce((prevHash, currVal) =>
(((prevHash << 5) - prevHash) + currVal.charCodeAt(0))|0, 0)
}
Арбайтен!
Совместная работа над грамматикой
Чтобы вместе весело работать над грамматикой и не лезть каждый раз в код, засунули правила в гуглотаблицу:
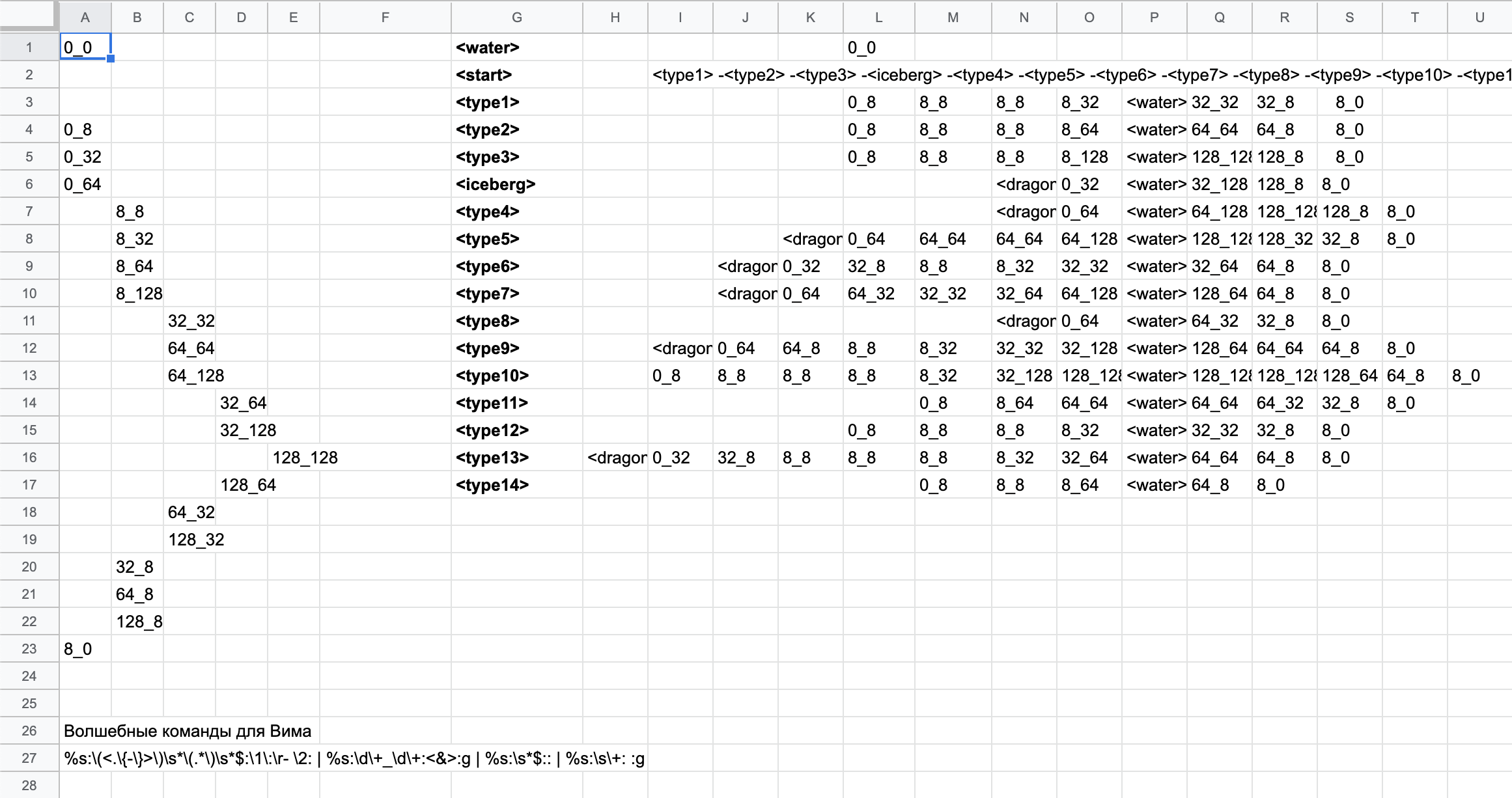
Слева я расставил все доступные в СВГ виды секций.
Справа, начиная со столбца G — правила грамматики. Тут можно использовать только те виды секций, которые перечислены слева.
Внизу — регулярное выражение для любимого текстового редактора Вим. Вставляю в Вим данные из правой части таблицы, запускаю команду, вставленная таблица преобразуется в формат YAML, который можно вставить в код. Знаки табуляции меняются на пробелы, лишние пробелы удаляются, и т. д.
Круги на воде и стрекоза
Они по сути — те же секции поплавков. Они лежат в том же входном СВГ файле, их положение в поплавке определяется грамматикой. Однако, они имеют хитрые размеры, чтобы грамматика не спутала их с какой-нибудь другой секцией. У воды размер верхнего и нижнего радиусов <0_0>, а у стрекозы <256_256>.
Такой подход позволяет на уровне грамматики определять,
- на каких секциях стрекоза может сидеть, а на каких — нет.
- Насколько часто стрекоза будет появляться.
- Между какими секциями поплавка будут расходиться круги по воде.
Удобно держать такие настройки в грамматике, это упрощает программу.
Итог
Кратко отвечу на Женины вопросы:
Как из текста получается набор переменных. Сколько там переменных, как они связаны, как влияют на форму.
Переменная одна, она делается из строки и является её хешем. То есть даже у почти одинаковых строк хеши будут сильно отличаться.
Эта переменная делает построение поплавка предсказуемым, определяя, какой из нескольких возможных способов превращения каждого токена будет выбран.
Что такое грамматика, какая она.
It’s breathtaking! They are all breathtaking!
как был устроен процесс совместной разработки.
Секции ребята рисовали в Фигме, дико удобно. Грамматику вместе редачили в таблице.